Digital Forensics: Processing at Scale
As companies and computing infrastructure grows and becomes more complex, so does the volume of data in security incidents. Scaling incident response to meet these growing needs can be challenging. This blog post will show how Turbinia might help you automate and scale to solve these problems.
Traditional digital forensic tooling is often focused on analyzing a small number of disks. However, in a large enterprise environment incidents can involve many computers or devices, centralized logs and various other artifacts. In these larger environments, the ability to process and analyze large amounts of data in parallel is necessary to respond in an efficient and quick manner.
Cloud Forensics
Cloud environments present new challenges to digital forensic analysis, however, they also have some useful properties that can help you when doing digital forensics at scale. Before getting into details, let's distinguish between doing forensics “in the cloud” versus “on the cloud”:- Performing digital forensics in the cloud means that you are using the cloud as a platform for digital forensic analysis. You can leverage the platform to analyze digital forensic artifacts (e.g. disks) that come from either inside or outside of the cloud environment. Performing forensics in the cloud allows you to dynamically scale your digital forensic processing by scaling your cloud computing resources. You have the ability to quickly and cheaply clone resources, e.g in a matter of minutes you can remotely snapshot a disk and make it available for processing in an isolated environment.
- Doing digital forensics on the cloud means analyzing cloud-specific artifacts, and can be vastly different from traditional digital forensics. There might be several computers running in a Kubernetes cluster, logs can be located in on-host or in central logs (e.g Stackdriver) and workloads can be challenging to trace when they run on containers.
Processing at scale
When multiple artifacts are involved, the actual processing can be done via embarrassingly parallel (or trivially parallelizable) means. Parallelizing the data processing and analysis can be as easy as processing multiple artifacts on separate systems, or even splitting up the artifacts and running on multiple systems.Turbinia is an open-source tool that can be used to scale and distribute your digital forensic processing. Turbinia is used for deploying, managing, and running distributed digital forensic workloads and is designed to automate the running of common forensic processing tools (i.e. Plaso, bulk_extractor, and strings, etc) as well as provides you with the ability to run custom tools. This automation enables you to process large amounts of evidence, and decrease response time by parallelizing processing.

Turbinia Architecture
Turbinia can run in many different types of environments depending on your needs and you can customize the installation to match your specific environment.- Cloud only: Turbinia can run completely in the cloud on the Google Cloud Platform, and uses cloud-native services such as PubSub, Datastore and Cloud Functions. All processing and data stays in the cloud.
- Local only: In local mode, Turbinia can run completely isolated from the cloud, and with local services only. In this case all processing and data stay local to your shared storage.
- Hybrid mode: In hybrid mode, the Workers and the server run locally, but the rest of the infrastructure uses managed cloud services to communicate and store metadata. This installation type will process data locally using shared storage similar to a local installation, but metadata is processed and stored in the cloud.

Turbinia architecture on Cloud
Here are the basic architectural components of Turbinia:
- Tasks: A Task is the smallest unit of schedulable work. They are responsible for running various tools to extract, process or otherwise work with data.
- Jobs: A Job is a larger logical unit of work that creates one or more Tasks to process a given piece of evidence. A Job can either create a single Task, or it can parallelize the work and create multiple Tasks. For example a Strings Job can generate two tasks, one to extract all ASCII strings and another to extract all Unicode or multibyte character strings.
- Worker: Workers are independent processes that run either in Google Compute Engine (GCE) instances or on local machines. They run continuously and wait for new Tasks to be scheduled.
- Evidence: Evidence can be anything that Turbinia can process. Examples include disk images, cloud disks, Plaso files, strings files, etc.
- Server: The main Turbinia process that waits for new evidence to be processed and generates Jobs and Tasks to be sent to the Workers to then run.
How it works
The Turbinia server can schedule processing on a configurable number of Workers, which can be scaled up and down to meet your processing needs. When a processing request is made, based on the type of incoming evidence that needs to be processed, the server will create a set of Turbinia Jobs that know how to process that type of evidence. These Jobs can then break the processing work into a number of Turbinia Tasks that are placed into a processing queue. Then the next available Worker from the pool picks up the task from the queue and executes it.
Processing evidence usually requires some preparation first. For example, attaching a cloud persistent disk to the Worker instance or copying the evidence from shared storage. The steps involved in preparing the evidence to be processed by Turbinia is handled by pre-processors, and any clean-up that needs to happen after processing is handled by evidence post-processors. In the cloud persistent disk case, evidence pre-processors first attach the disk to the Worker executing the scheduled Task and then mount the disk so that the Task code can access it. After the Task has completed, the post-processors will unmount and detach the disk from the Worker.
Processing a piece of evidence can in turn generate more evidence that is fed back into the system to be further processed by other Turbinia Jobs, creating a cycle of processing that continues until all data has been processed. The following example shows how one of Turbinia's Plaso Job can generate new evidence from an initial disk image.
Example: Here are the steps for one cycle of processing:
- A new processing request for a disk image is sent to the Turbinia Server.
- The Turbinia Server creates a set of new processing Jobs/Tasks, including Plaso, that can process disks.
- The Plaso Task runs and generates a Plaso storage file (SQLite) containing the info that was parsed from the disk image, and a reference to this gets returned to the Server as new evidence to process.
- The Server then creates a Psort (tool to post-process Plaso files) Job to process the new Plaso file evidence. When it runs it will generate a CSV file containing a timeline of all parsed events which is also passed back to the Server as new evidence.
- Finally, a simple Grep Job is scheduled to extract entries that match any keywords passed in with the initial request.
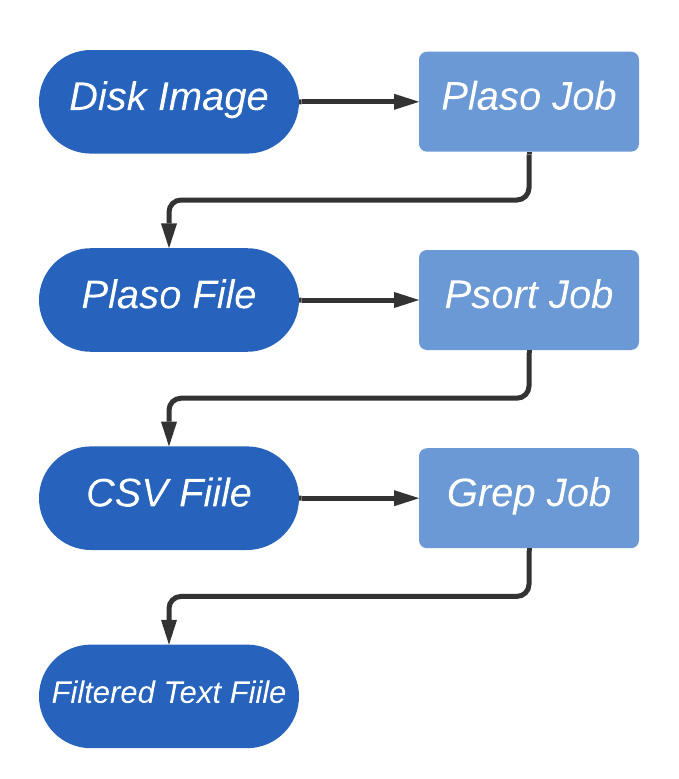
Graph showing evidence → Job → evidence cycle of processing.
Putting it All Together
In a scenario where you have some potentially compromised GCE instances on which you want to start your analysis, you don’t want to tip off the attacker that you are investigating and so you don’t want to take down any instances. Instead, you take disk snapshots and clone them into a dedicated cloud project for later forensic analysis. By having a separate analysis project you can isolate the environment from the compromised project and ensure you have a copy of the disks from the instances under investigation. Once you have a snapshot of the disks you can use Turbinia to process the disks in parallel with common forensic tools.Below is an example showing what happens when using Turbinia to collect and process disks from these potentially compromised machines:
- Snapshot the disks from the compromised instances.
- Copy these snapshots to a dedicated cloud project for analysis.
- Depending on the current number of the Workers, we may opt to increase the size of the Worker pool for more processing throughput.
- Send requests to the Turbinia Server to process the disk copies via the process listed above.
- As processing completes, the Turbinia Workers will write the resulting files and output evidence to Google Cloud Storage (GCS), including the .plaso evidence files.

Processing cloud disks with Turbinia
Summary
If you are looking to scale and automate your digital forensics workflows to more efficiently respond to security incidents, Turbinia is a free and open source tool that can help you with that. In addition to the pre-built Jobs for common processing Tasks, users can create new Jobs for just about any custom program by modifying a few lines of code from a base template, making Turbinia resourceful in various environments. See here for more information on how Turbinia works, or here for installation instructions.In the next article about Turbinia we will go in-depth on how to use the system and explain in detaile how it can help you when responding to a wide range of incident types.
_________________
Learn more about the basics of incident response and forensic analysis in the new Google Cloud book: Building Secure & Reliable Systems. Best Practices for Designing, Implementing and Maintaining Systems, Chapter 17.
In this book experts from Google share best practices to help your organisation to design scalable and reliable systems that are fundamentally secure.
The book is available for free at https://landing.google.com/