Turbinia's API Evolves: A Comprehensive Overview of the Latest Enhancements
Turbinia's API Evolves: A Comprehensive Overview of the Latest Enhancements
Authored by Igor Rodrigues, copied with permission.
Introduction
Turbinia is an open-source framework for deploying, managing, and running distributed forensic workloads. Turbinia used to rely on the command-line tool turbiniactl for the user to interact with Turbinia, which is now being replaced by Turbinia API. This blog post will discuss new features added to the Turbinia API server, which simplifies, optimizes, and enhances this process. The API offers a variety of endpoints (Figure 1) adding new functionality to Turbinia in addition to features ported from turbiniactl. The API can be accessed through a new Web UI or through the new command-line tool, turbinia-client. The turbinia-client sends HTTP requests to the API server and outputs a formatted version of the API response. turbinia-client offers new features and improved formatting for a more intuitive experience.
This blog post is intended for analysts and developers who are familiar with Turbinia. It will demonstrate the new features added to the API, how to use them, and what their output is. It will also discuss how these new features improve Turbinia and what areas could still be improved.
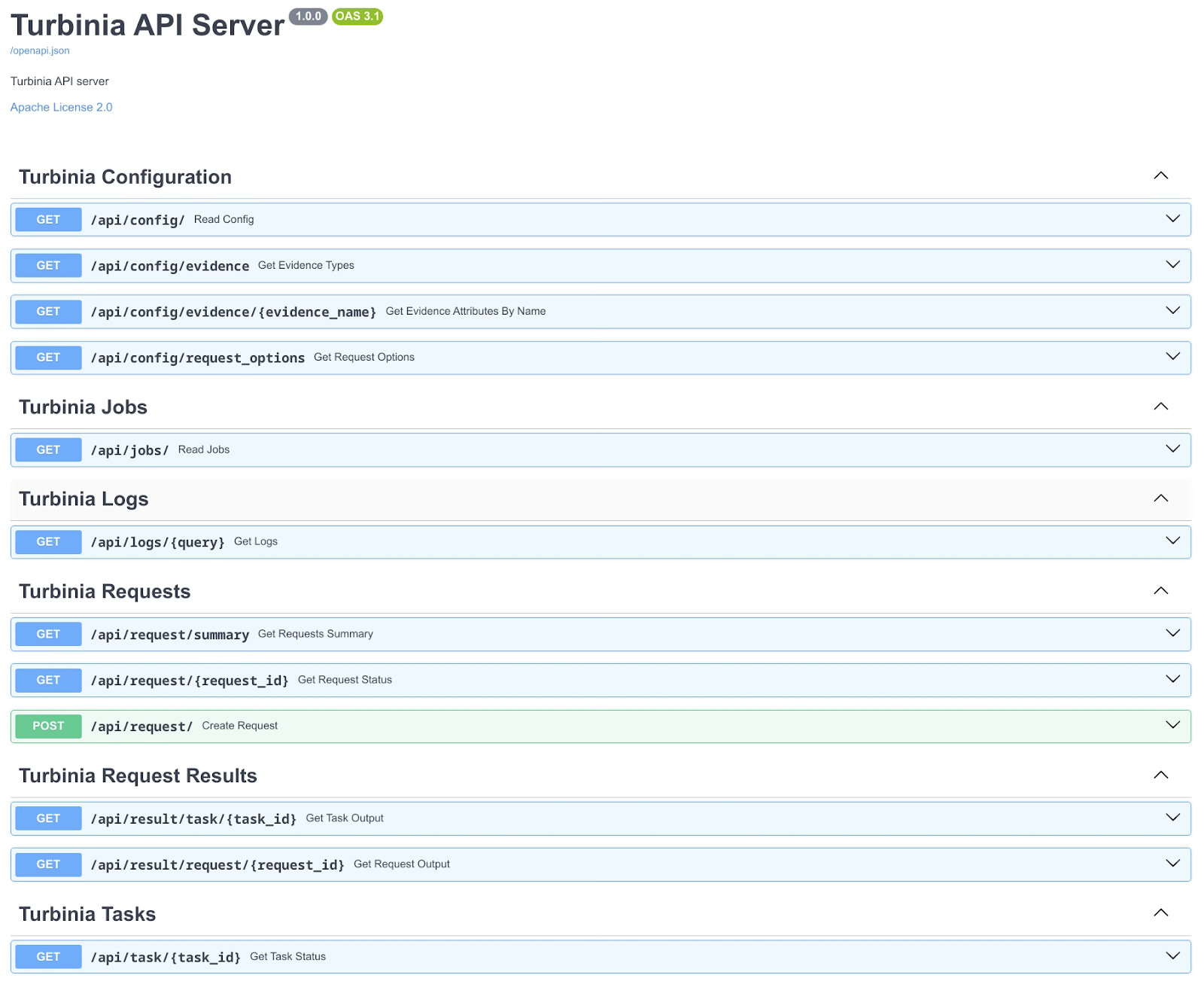
Figure 1: Turbinia API documentation page
With the introduction of this API, Turbinia is moving away from using native Google Cloud Platform (GCP) functionality and adopting Redis as its main storage data frame. This post will also discuss the ongoing integration between Turbinia and Redis. Redis is an in-memory key-value data store used to save information about previous and ongoing Turbinia tasks. Redis supports a variety of data structures, with strings being the type used to store Turbinia tasks. The task objects are serialized to a JSON string, which is stored in Redis using an identifier as a key to retrieve the string.
Challenges faced with the new API
Note that in the following sections the term evidence is used to describe input data, similar to the terminology used by Turbinia.
Uploading Evidence
The first challenge we faced was not being able to upload evidence directly to Turbinia. The previous process used SSH as a workaround, but was not viable due to the lack of a shared file system. To make this process simpler, we implemented easy means to upload files to the server via the API before processing them.
Metadata
The next challenge was that Turbinia did not store evidence metadata, so there was no way to retrieve information about when processing was finished. Once a task was finished, all attribute values of the Evidence objects were discarded, so it was not possible to access information like the creation time, local path, and last update. This made it difficult to analyze evidence metadata and debug issues. Additionally, the only information about the evidence available in the Web UI was the evidence name, and the evidence size was not calculated for most types of evidence. To address these challenges, we implemented a new object type in Redis to preserve this information, which is also more optimized than the previous ways we stored Turbinia metadata.
Feature Parity
Another challenge was ensuring we reached feature parity with the old turbinia client. One example of this was the lack of the statistics command (Figure 2). In addition to porting these commands, we took the opportunity to produce a more concise output by reformatting the Markdown text.
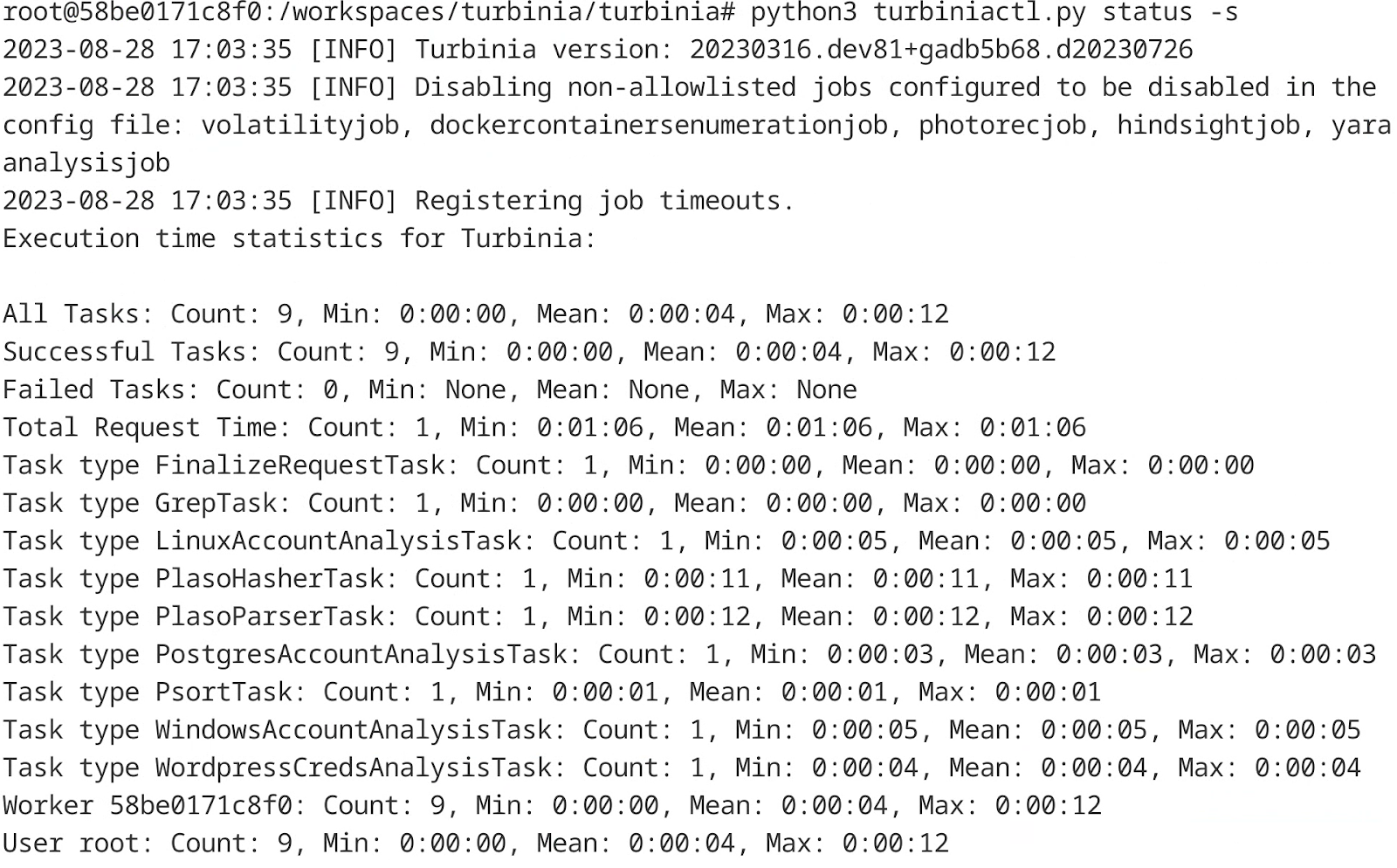
Figure 2: Output of statistics command in turbiniactl
Restoring Redis Data
Yet another challenge was retrieving, backing up, or restoring data from the Redis server was difficult to do. The fix was to create a script that allows admins to access content within Redis, such as being able to query, delete, dump, and restore multiple tasks at once.
Improvements on Turbinia evidence
New evidence endpoints and commands
A new API route (/api/evidence) was created to organize all API endpoints related to evidence (Figure 3). As a result, the existing evidence endpoints under /config were moved to the new route, along with four new endpoints.
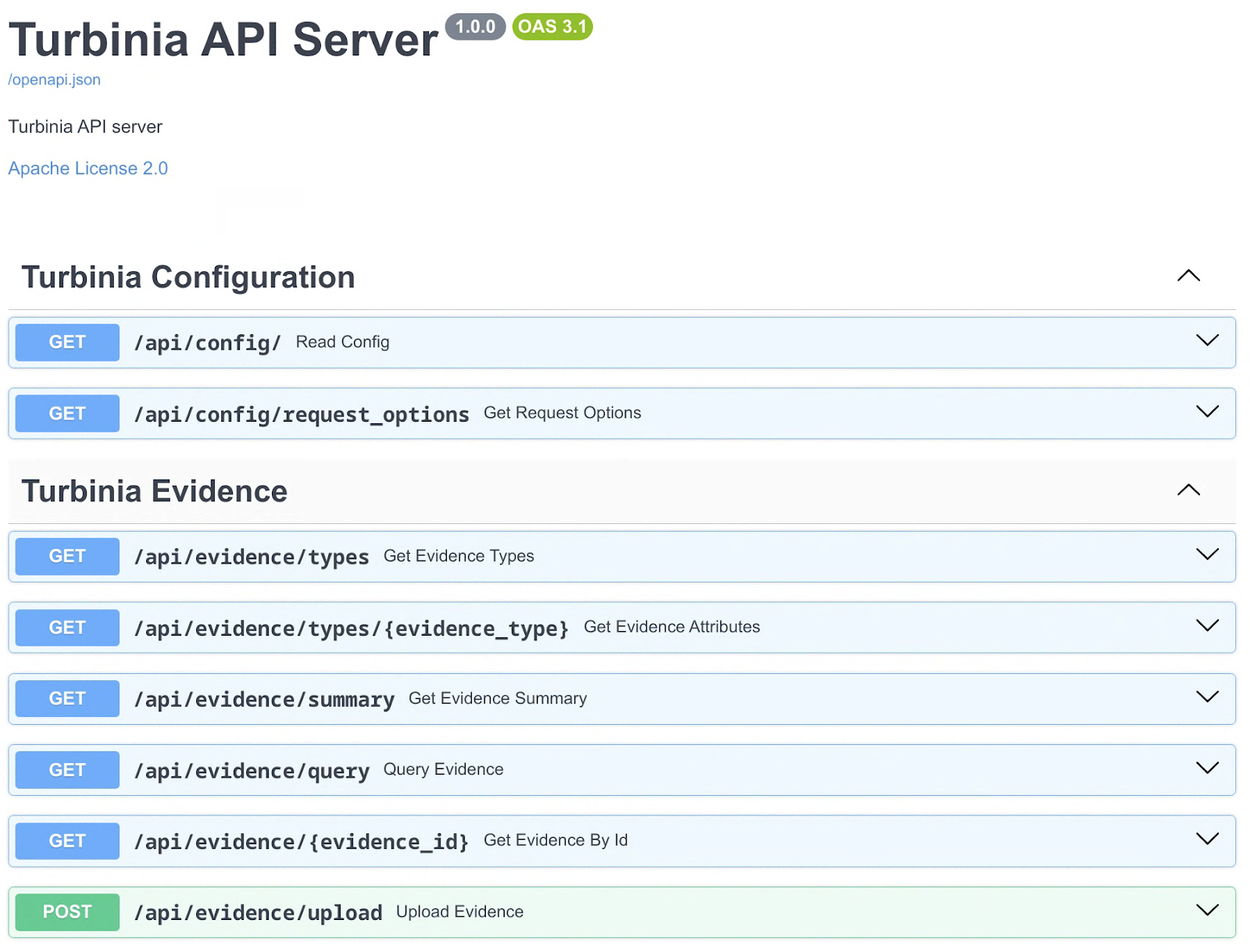
Figure 3: New Turbinia Evidence route in the API
Additionally, a new evidence command group was added to the client (turbinia-client evidence) which groups all commands related to evidence (Figure 4).
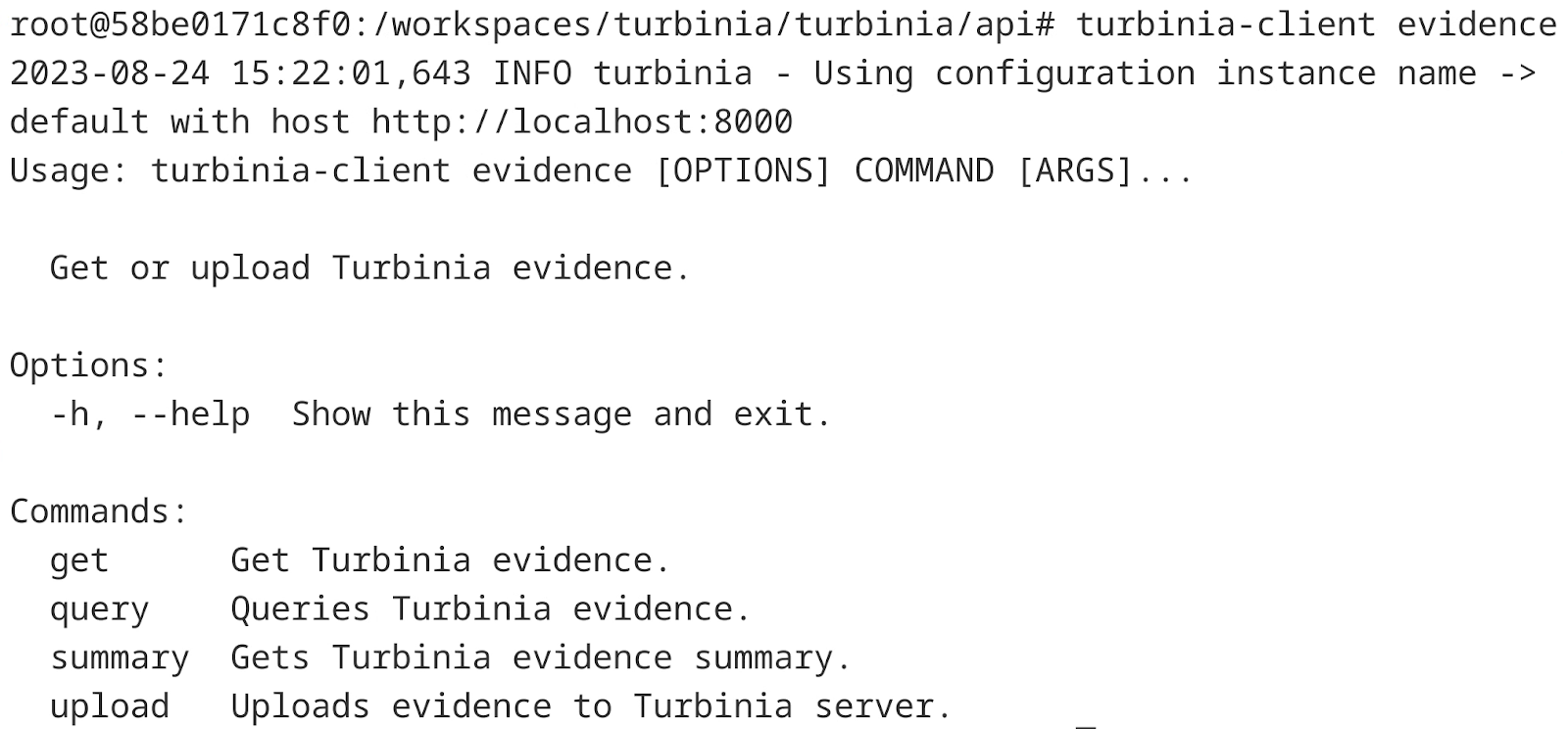
Figure 4: New evidence command group
Uploading evidence files to the Turbinia server
A new endpoint (Figure 5) was implemented to upload evidence files to the API (api/evidence/upload).
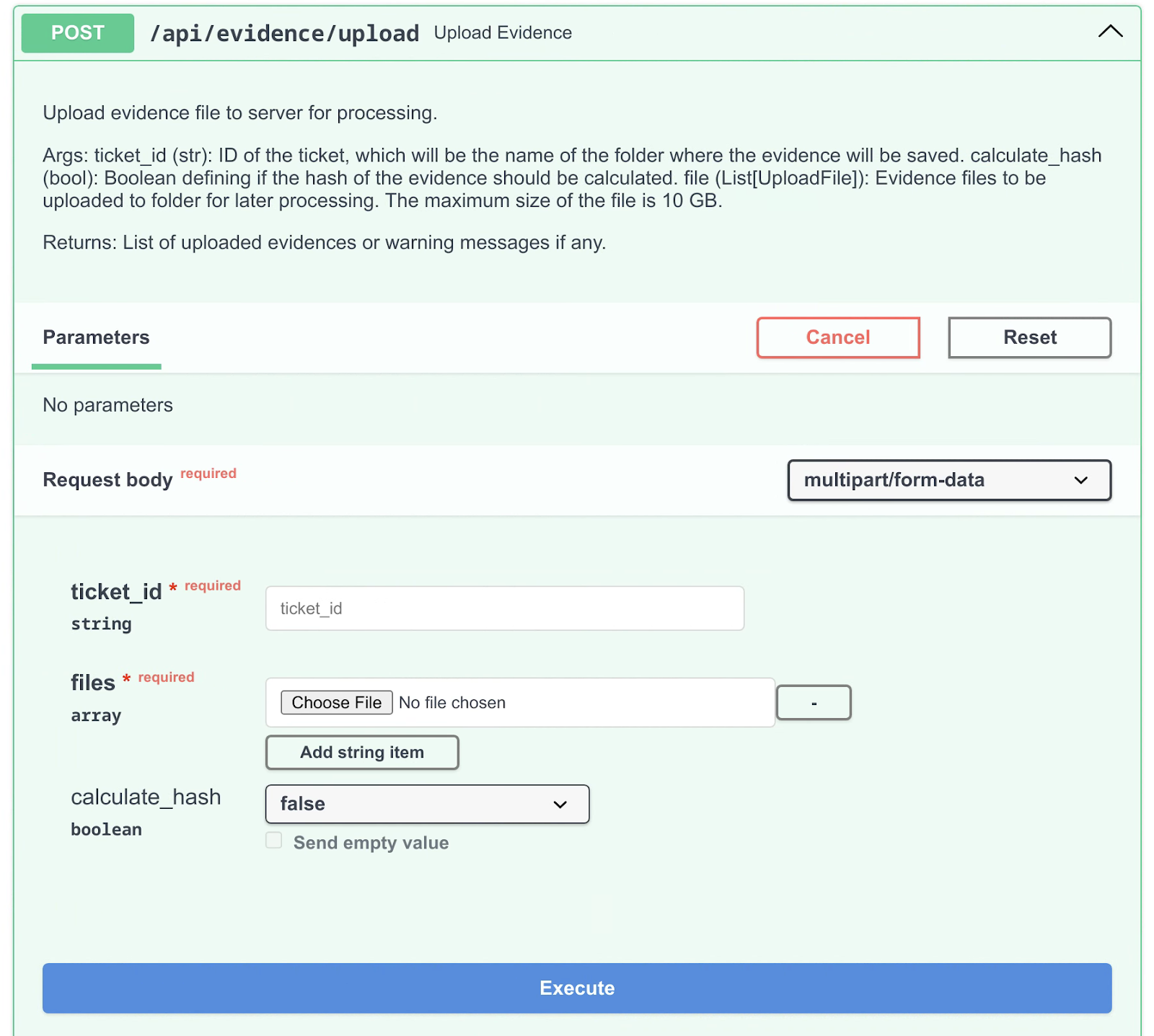
Figure 5: New evidence upload endpoint in Turbinia API
The evidence upload command was implemented in the turbinia-client tool (turbinia-client evidence upload). This command allows users to upload multiple files and directories to the Turbinia server at the same time (Figure 6). If a directory is passed, the tool will upload all files inside the directory. The command also takes a ticket ID as an argument, which is used to name the directory where the uploaded files are saved, grouping evidence of the same case together. The files uploaded to the server are saved in a path specified in the Turbinia configuration, inside a subdirectory of the ticket ID provided by the user. There is also a flag for calculating the SHA3-224 hash of the file (-c), which can be used to check if the upload was correct, but also has the disadvantage of slowing the server down, especially for bigger files, so should be used on a need-basis. Finally, there is an option for outputting JSON (-j) instead of Markdown.
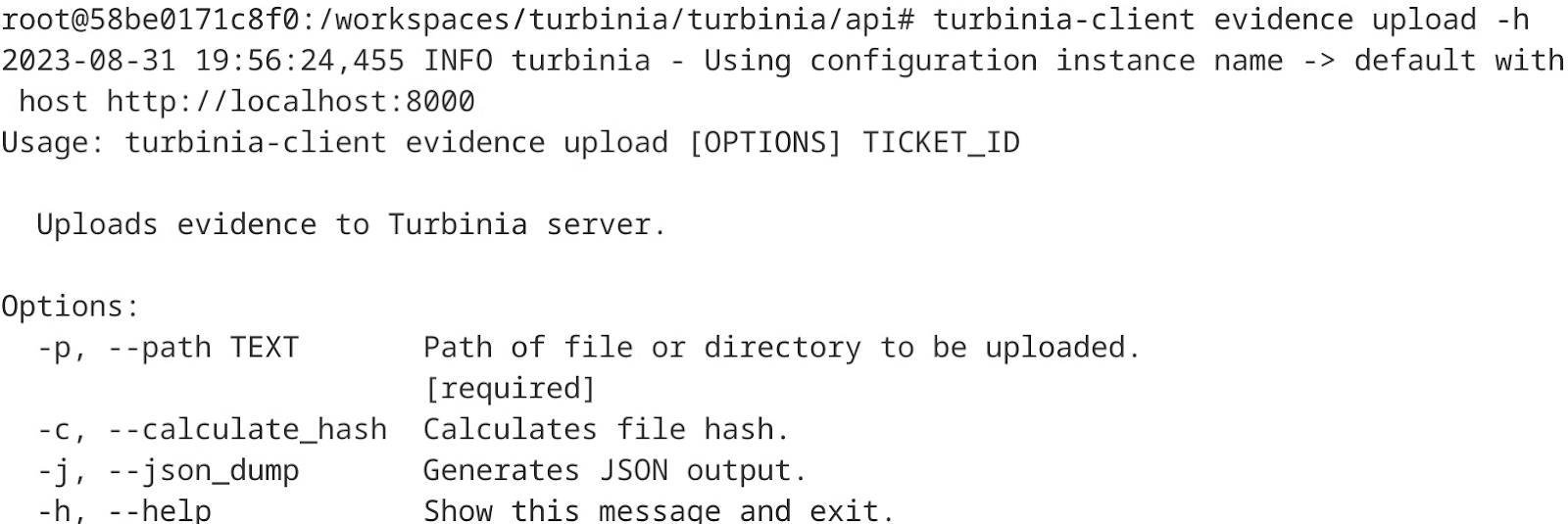
Figure 6: New evidence upload command in turbinia-client
When the upload is complete, the server returns information about each uploaded file, including the saved file name, file path, and size. In the example below, the file log.txt is uploaded along with the files inside the directory “storage,” and their hashes are calculated. The server then returns information about each uploaded file (Figure 7).
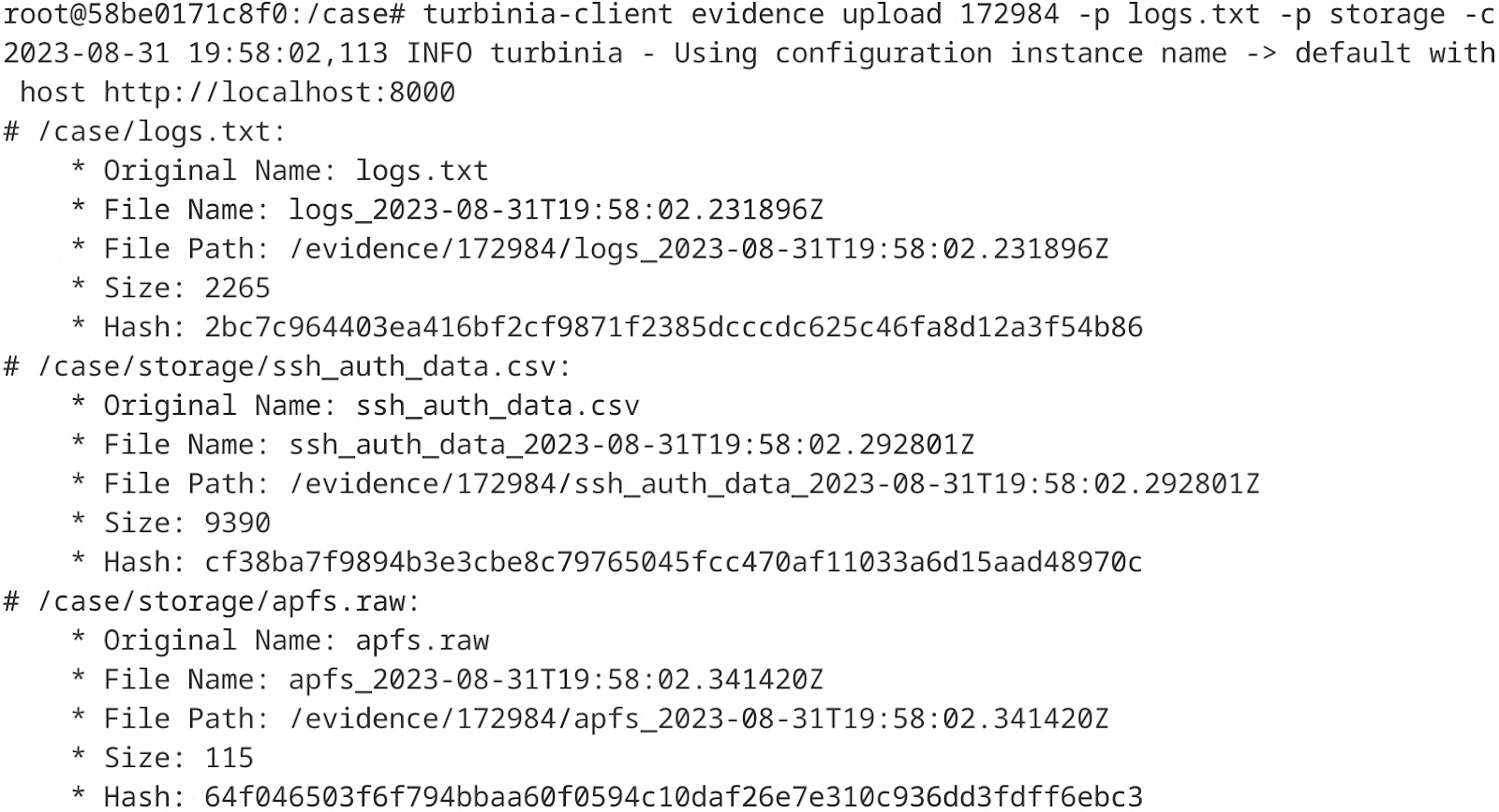
Figure 7: Example of evidence upload using turbinia-client
Storing and retrieving evidence metadata
When a Turbinia task is completed, all attributes of the objects are discarded, making it impossible to retrieve this information later on unless it is stored in Redis like the TurbiniaTasks. Therefore, it is important to also save evidence metadata in Redis as the attributes can be useful for digital forensics analysis and software debugging. To save the evidence metadata in Redis, the id attribute was added to the Evidence class, along with three other fields: tasks, creation_time, and hash. Additionally, the function used to get evidence size was modified to include more evidence types.
New functions were added to the Redis state manager to write and update evidence objects in Redis, which are called by the Turbinia task manager. Similar to the task keys, the evidence keys are composed of TurbiniaEvidence:{evidence id}. While TurbiniaTask objects were stored as strings in Redis, the new TurbiniaEvidence objects are stored as hashes, a collection of field-value pairs. Each field is the name of an attribute of the original Python Evidence object, and each value is the corresponding value serialized as JSON. This reduces the runtime of retrieving and setting an attribute of TurbiniaEvidence. Because of the use of more optimized functions, many evidence commands that depend on retrieving and updating attribute values are faster than with TurbiniaTask (Table 1).
Table 1: Runtime of functions for TurbiniaTask and TurbiniaEvidence objects
Users needed a way to easily access the information stored in the TurbiniaEvidence objects, so new functions were added to the Turbinia API to query and summarize the evidence objects. New endpoints were added to the API so that users could easily use these functions to access evidence metadata. Furthermore, many smaller functions were added to handle hashed objects in the Redis State Manager, which are not directly accessed by the users but can be later used by the developers to implement other types of Turbinia hashed objects in Redis.
Get evidence command
A new endpoint (Figure 8) was added to the API to retrieve information about stored evidence metadata (/api/evidence/{evidence_id}). This endpoint takes an evidence ID as a parameter and returns information about the evidence.
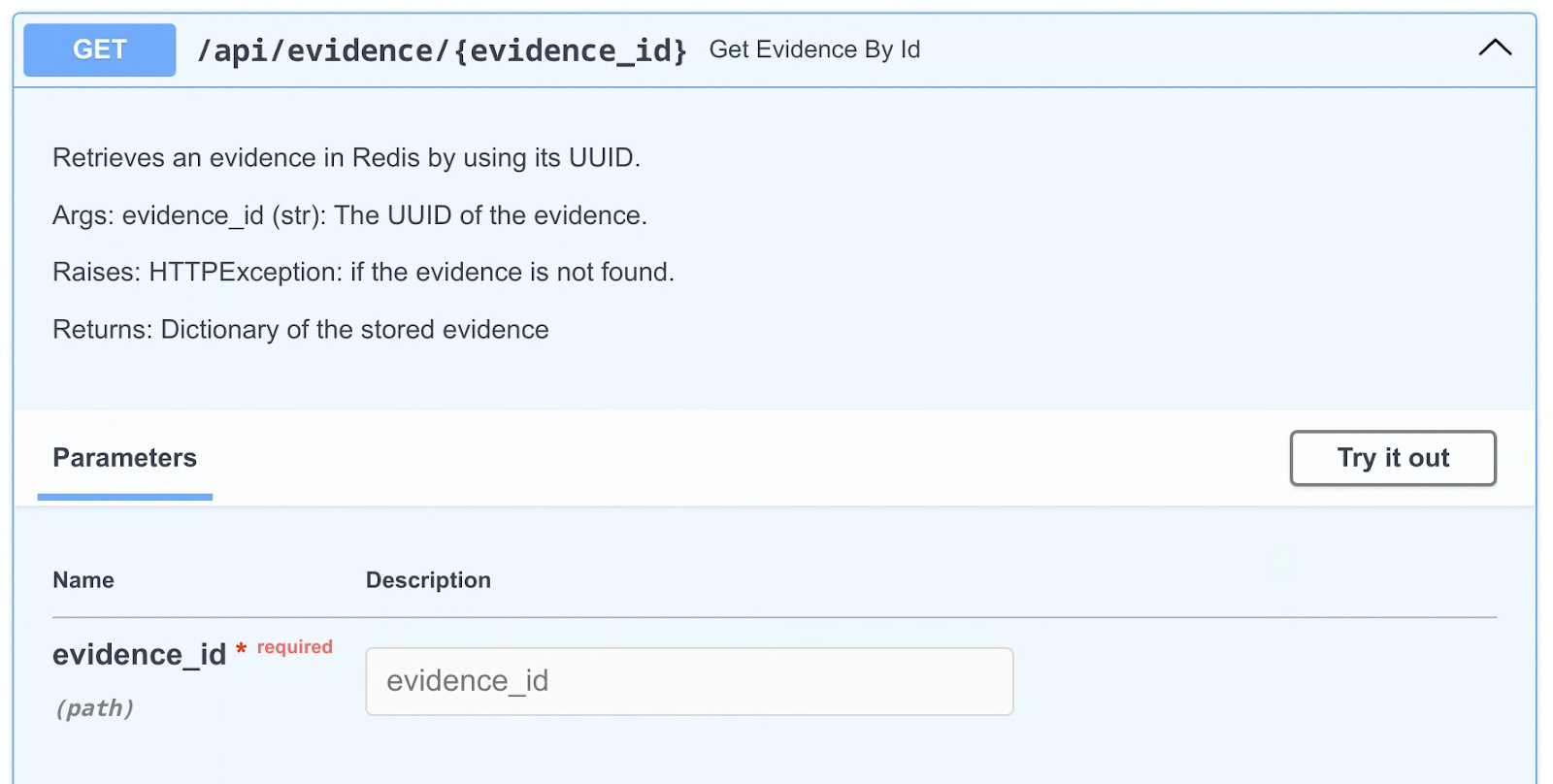
Figure 8: Get evidence endpoint in Turbinia API
A new command (turbinia-client evidence get) was added to the command-line client for retrieving information from the new endpoint (Figure 9). By default, the command returns the most important attributes of the evidence, formatted in Markdown. Using the flag show_all (-a), the server also outputs the fields that are not marked as important. Using the json_dump flag (-j), the data is output as JSON.

Figure 9: Get evidence command in turbinia-client
In the example below, the user runs the get command with no flags and the server replies with Markdown-formatted evidence data (Figure 10).
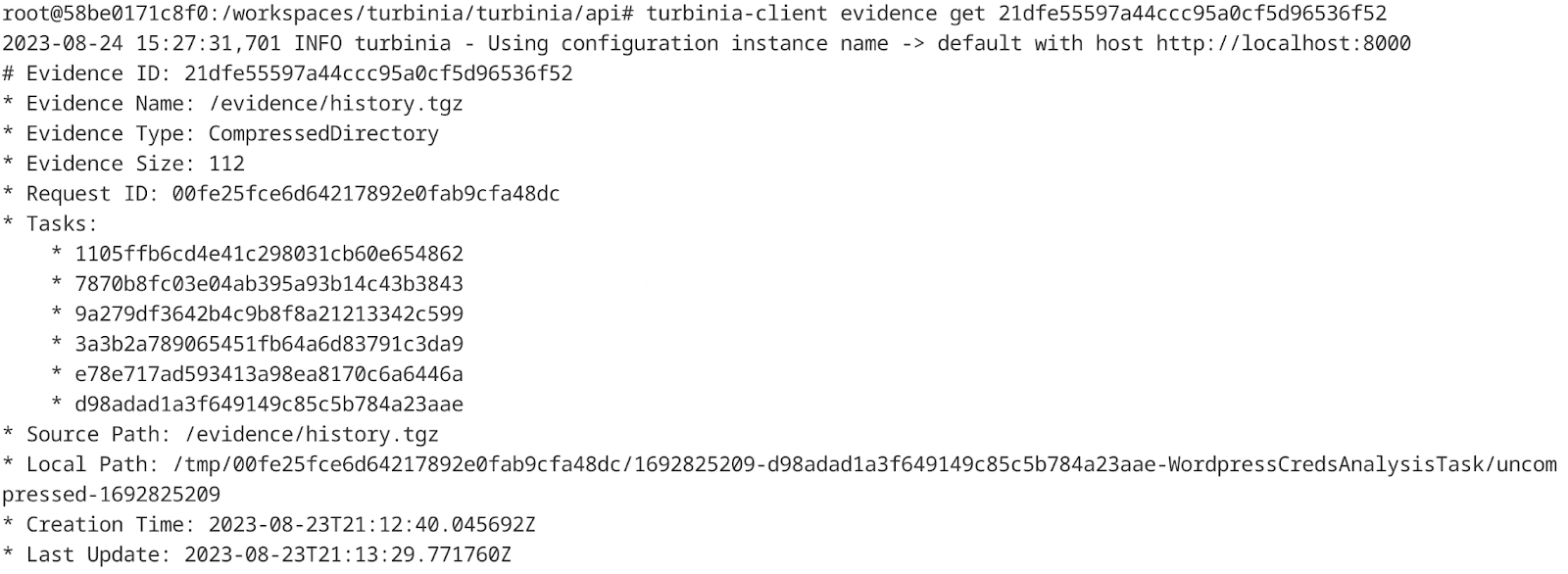
Figure 10: Example of getting evidence using turbinia-client
Query evidence command
The evidence query endpoint (Figure 11) was added to Turbinia to allow users to query for evidence with a specific attribute value (api/evidence/query). The user can specify the format of the output, which can be keys, values, or a count of items found. The server will then return all evidence items that have the specified value in the specified attribute.
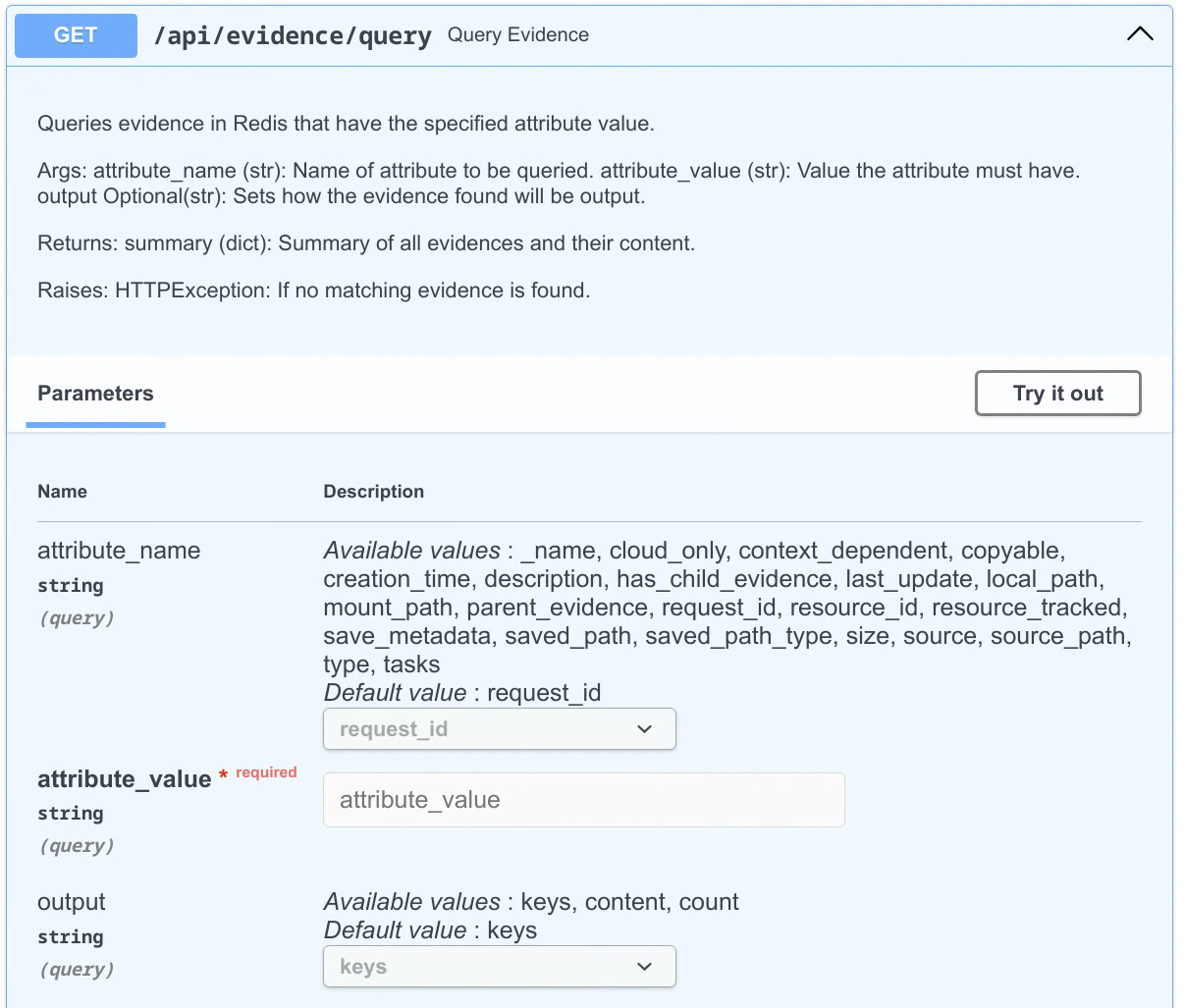
Figure 11: Query evidence endpoint in Turbinia API
A command (turbinia-client evidence query) was implemented in the client to use the query endpoint (Figure 12).
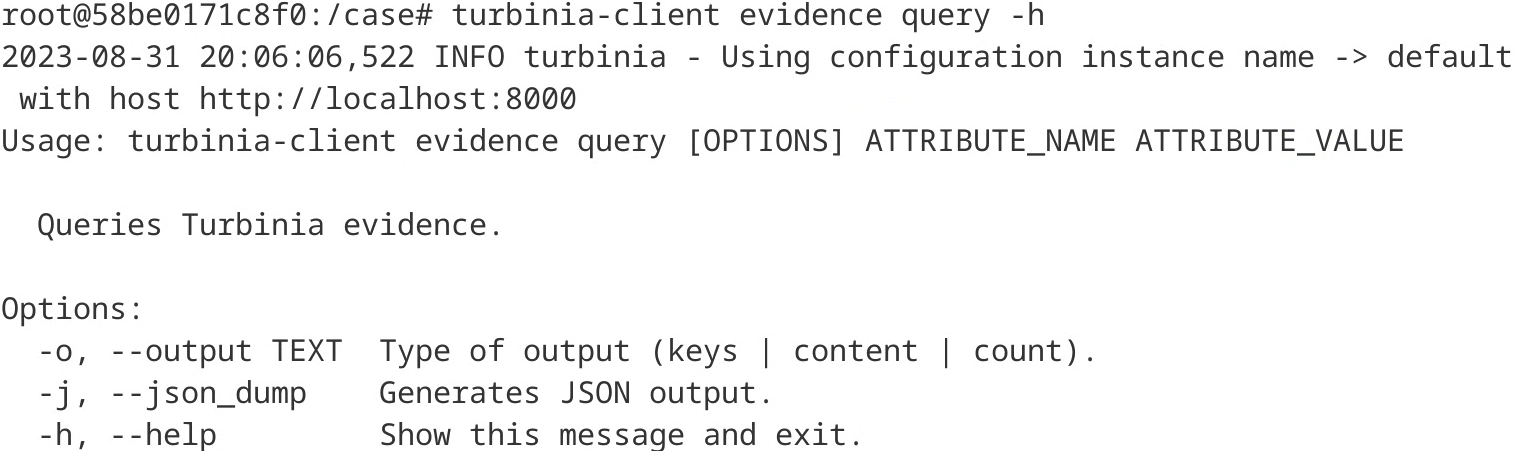
Figure 12: Query evidence command in turbinia-client
In the following example (Figure 13), the user queries the API for evidence that belongs to a specific request ID. The user does not specify any flags, so the server returns all of the evidence keys in Markdown format.

Figure 13: Example of querying evidence using turbinia-client
Evidence summary command
Another endpoint added to the API (Figure 14) was the evidence summary query endpoint (api/evidence/summary), which allows users to get a summary of all evidence. The user can specify the format of the output just like the count endpoint.
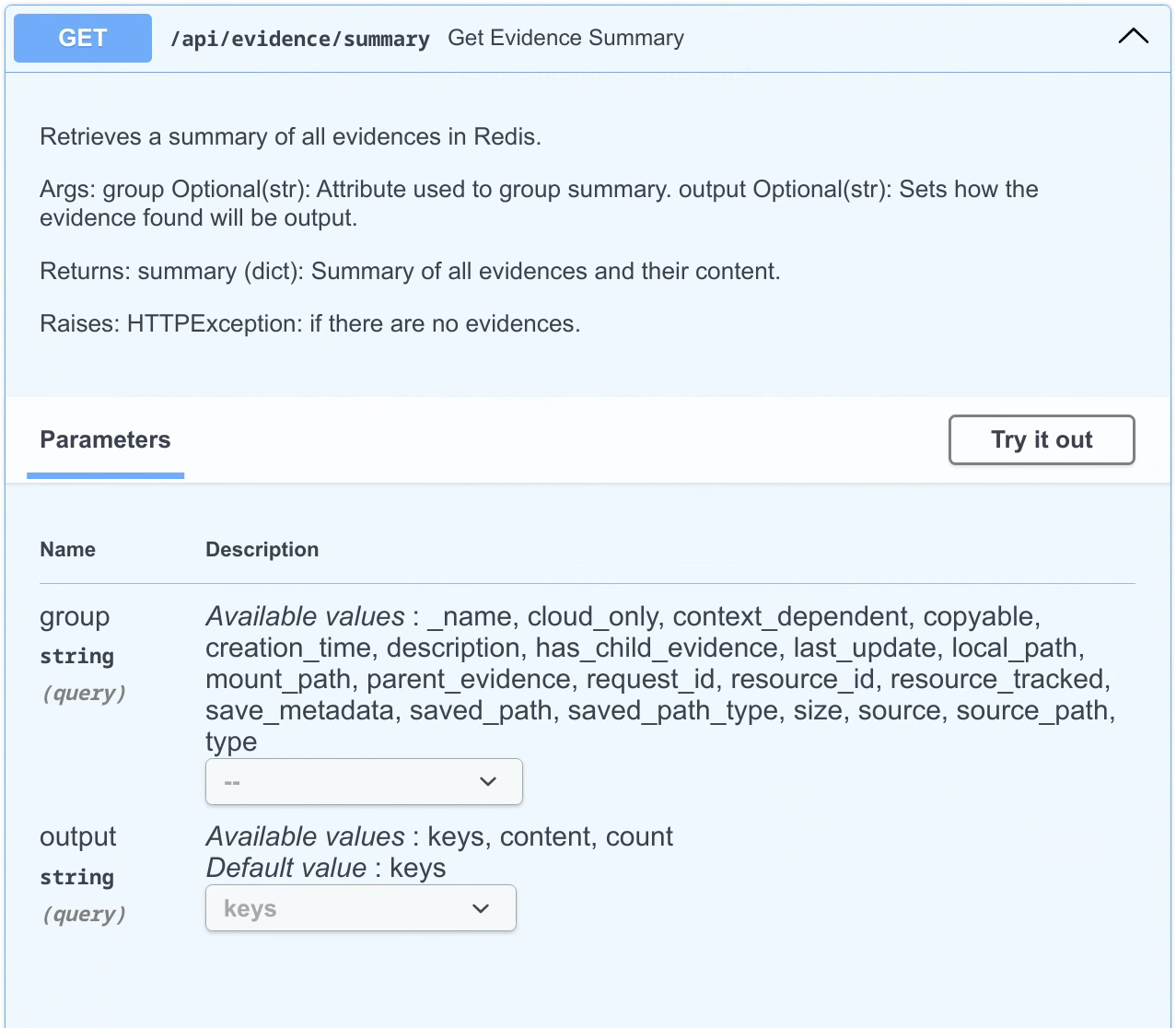
Figure 14: Evidence summary endpoint in Turbinia API
A command was implemented in the client to use the query endpoint (turbinia-client evidence summary). In the following example, the user gets all evidence, grouping evidence with the same request ID (Figure 15). The server then returns the evidence keys in Markdown format.
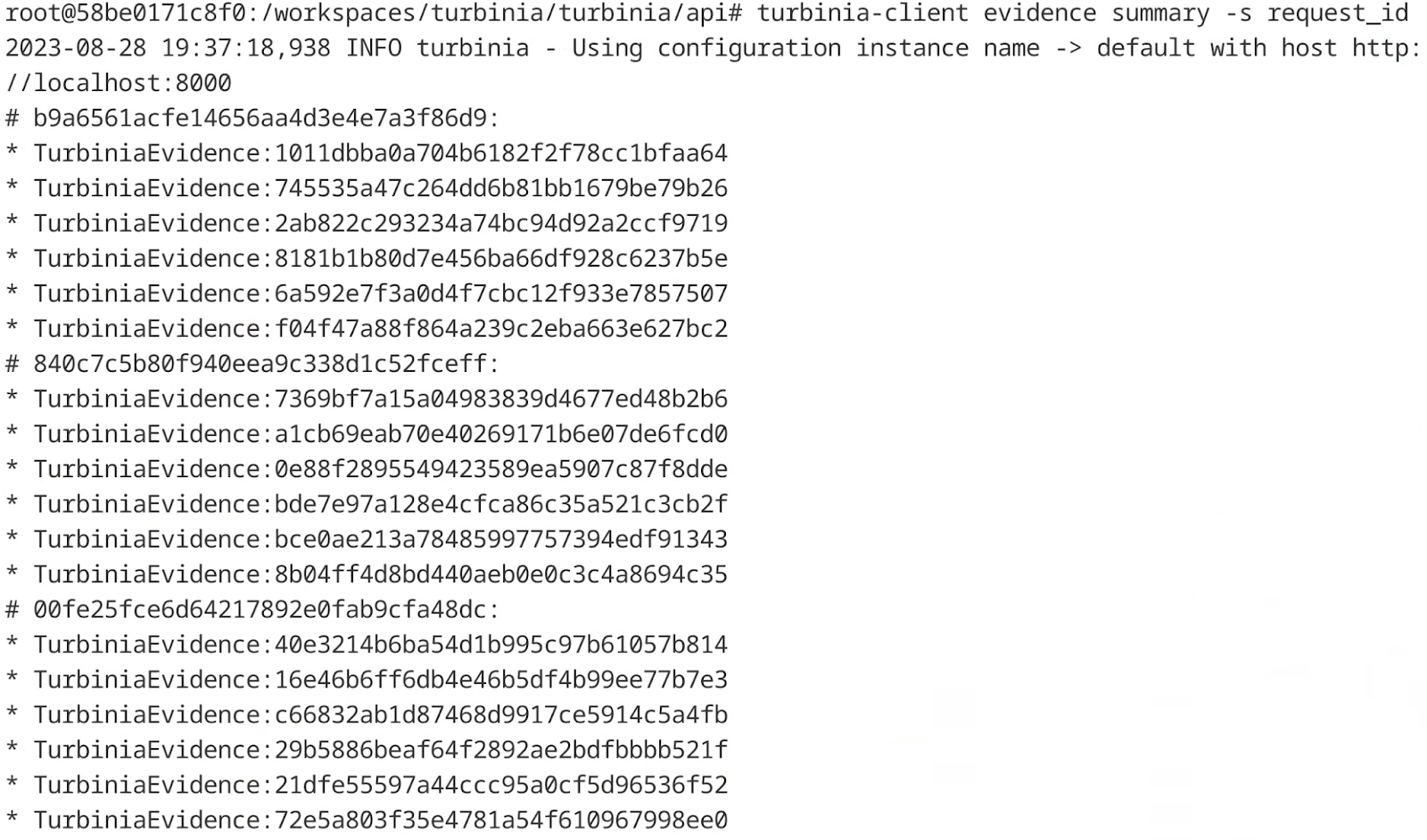
Figure 15: Example of evidence summary using turbinia-client
More information about evidence displayed on Web UI
In the Web UI, the evidence name was added to each request in the Request List header (Figure 16, 1 - blue highlight). Additionally, the evidence ID can now be viewed under Associated IDs (Figure 16, 2 - red highlight) and the size under Processing Details (Figure 16, 3 - green highlight). These changes make it easier for users to find information about evidence files.
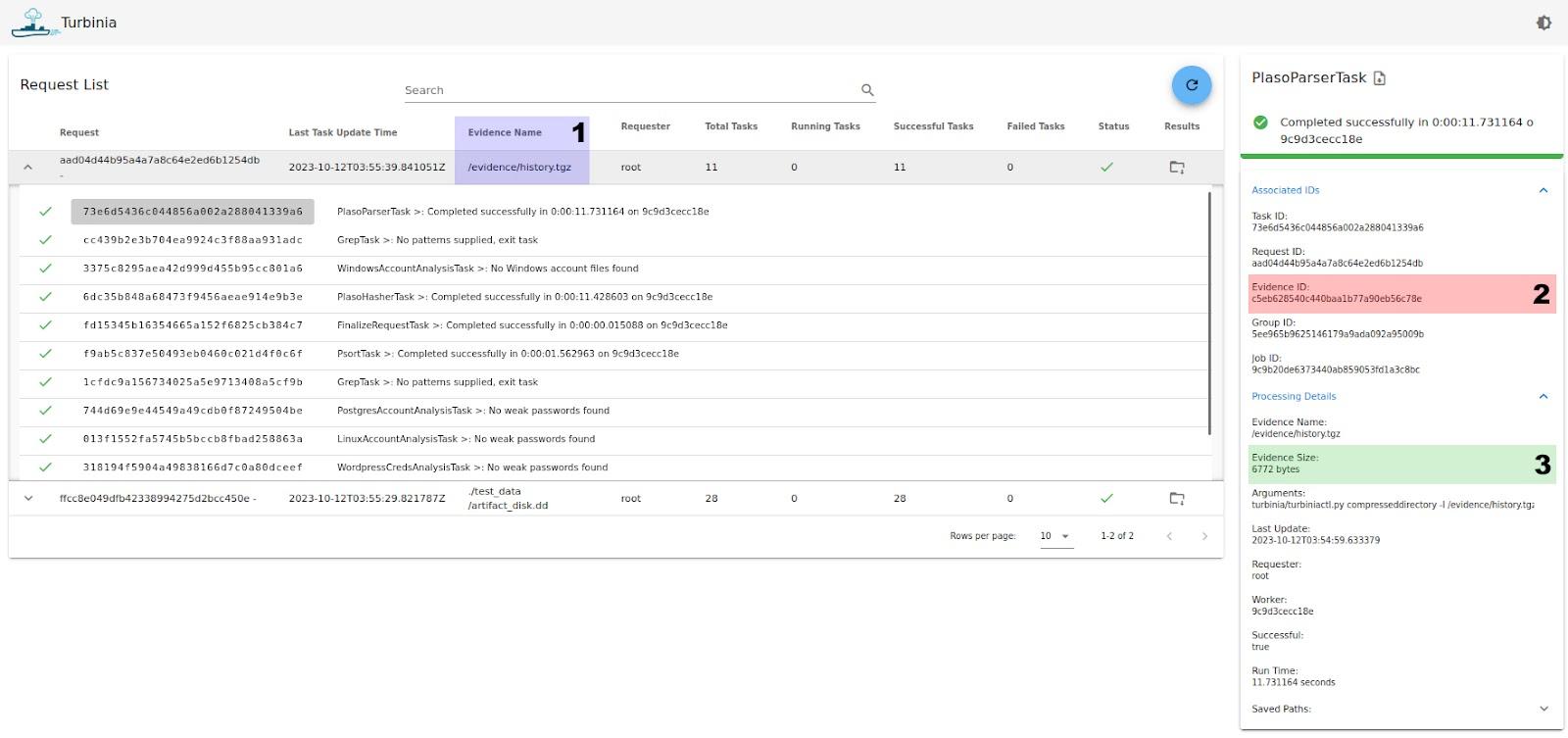
Figure 16: Turbinia Web UI with highlighted changes
Improvements on Turbinia tasks
Statistics command ported from turbiniactl
A new endpoint (/api/task/statistics) was implemented to provide task runtime statistics like in turbiniactl. The endpoint outputs the same information as the old command but in JSON format. A statistics command (turbinia-client status statistics) was also added to turbinia-client (Figure 17), along with the same filters as in turbiniactl: days, task_id, request_id, and user. Moreover, the default markdown command was reformatted with the pandas library to be more organized. The option to output the statistics as CSV (-c) was ported, and a new option was added to output as JSON (-j).
Figure 17: Statistics command usage in turbinia-client
The following example shows the reformatted output of the statistics command in the new turbinia-client (Figure 18). Compared to the output in turbiniactl (Figure 2), it is possible to see that the information is now more organized.
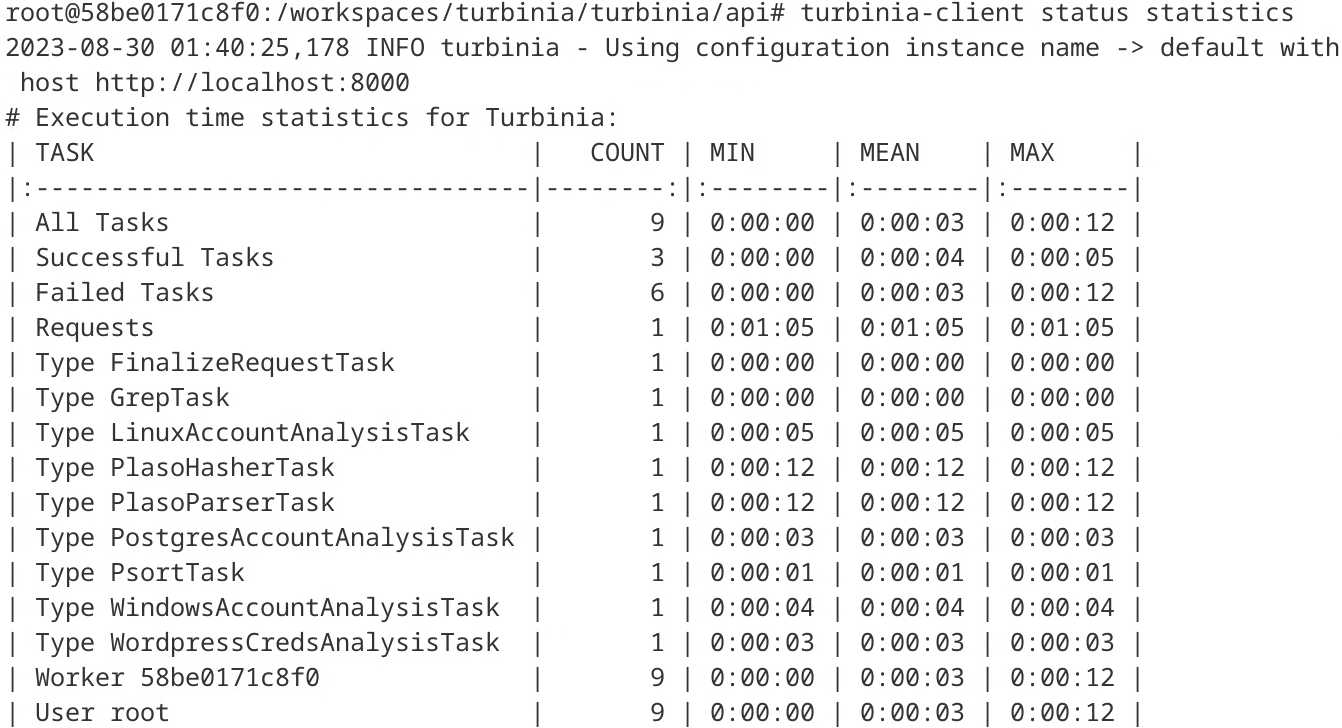
Figure 18: Output of statistics command in turbinia-client
Workers command ported from turbiniactl
Similarly to the statistics command, a new endpoint /api/task/workers was implemented to get the status of the workers. This endpoint lists all workers with their running and queued tasks. A new command was added to turbinia-client (turbinia-client status workers), which outputs the same information in Markdown (Figure 19) as turbiniactl. There is also a new feature to output the information in JSON, like the statistics command.
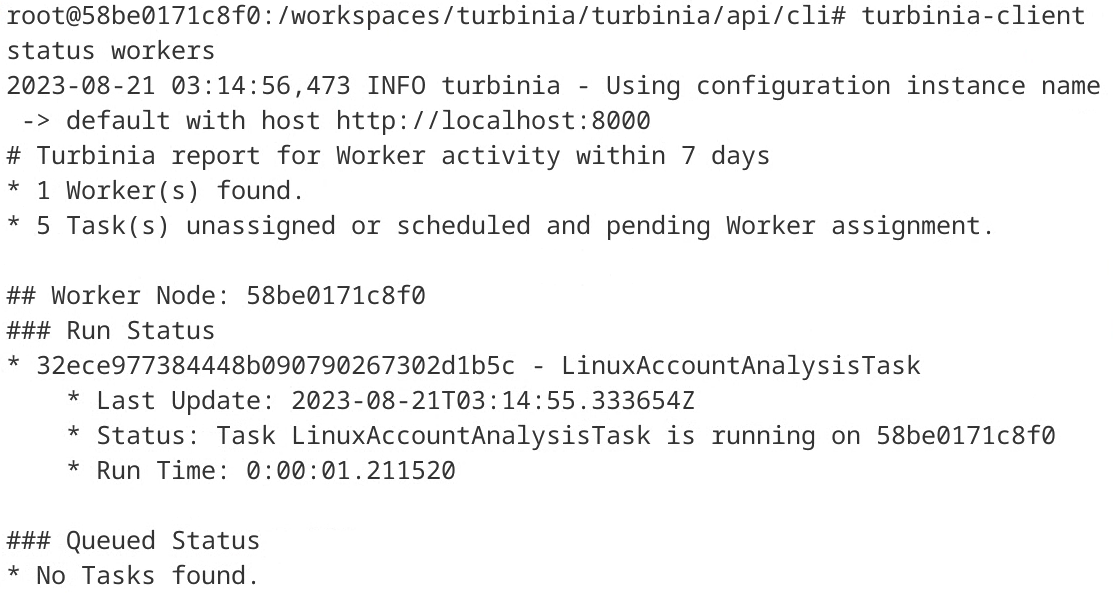
Figure 19: Output of workers command in turbinia-client
Reformatted task and request output in turbinia-client
The task markdown report in turbinia-client was reformatted to only show essential information for low-priority tasks. A new option, show_all (-a), has been added to the command to show all fields, regardless of priority. This change will also affect the tasks in the requests markdown report. Additionally, the requests report has been reformatted to order tasks by priority.
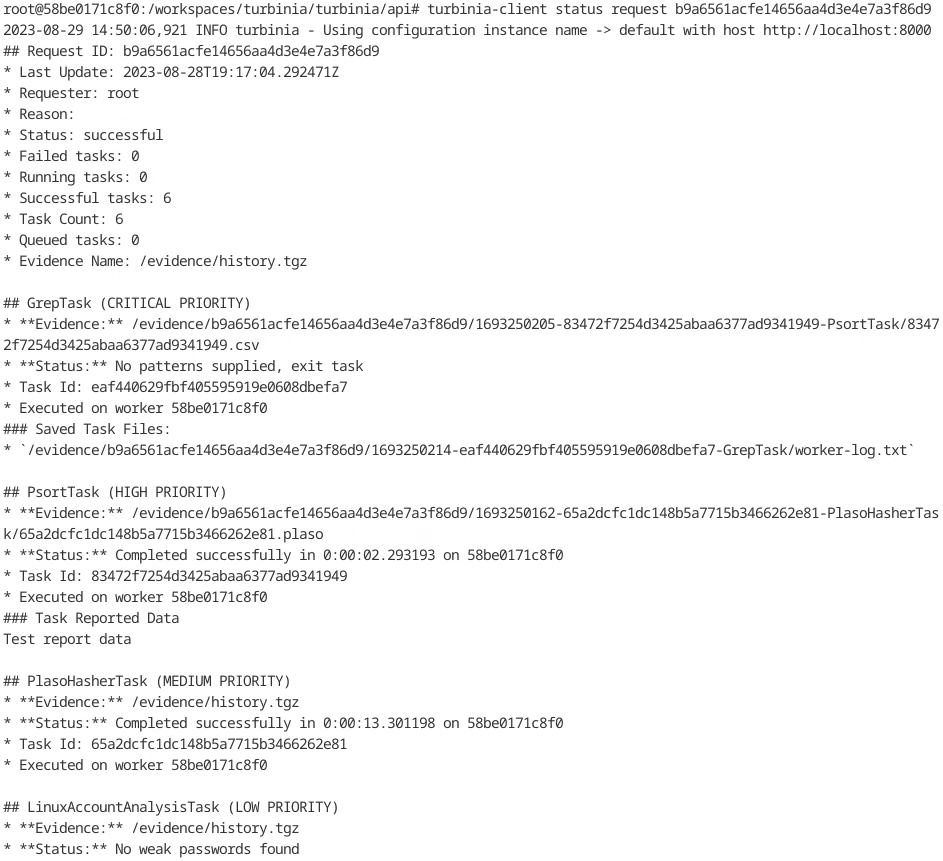
Figure 20: Reformatted request output in turbinia-client
New script redis-tools.sh to handle TurbiniaTask keys in the server.
A new script called redis-tools.sh has been created to make task information in Redis more accessible. It has the following functions:
Query: This function queries specific Task objects. It can output the keys, the task content, or a count of items found. This is useful for getting the metadata of specific tasks or all of them at once.
Delete: Deletes tasks matching the passed attribute value. This function is useful for deleting all or specific keys at once.
Dump: Dumps tasks matching the passed attribute value. This is useful for backing up all or specific keys.
Restore: Restores all keys dumped to a specified folder. Useful for restoring the server when needed.
The following example shows the script being used to dump all keys belonging to a specified request to the folder storagefolder (Figure 21). Before dumping, the script outputs the keys found and asks the user if the keys should be dumped.
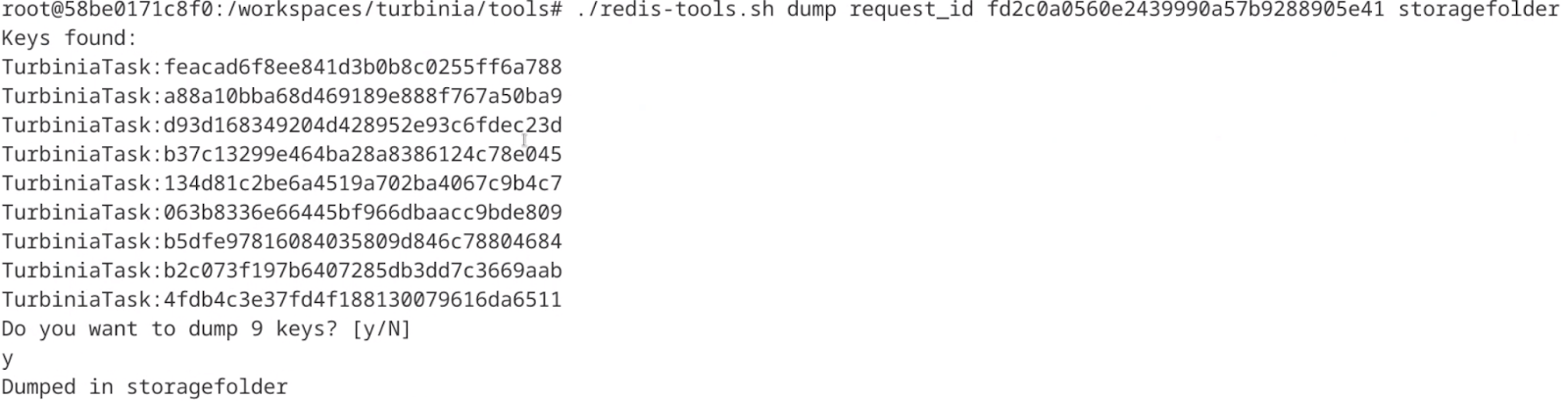
Figure 21: Output of redis-tools.sh dumping all keys of a request
Conclusion
The new updates to the Turbinia API bring the following improvements:
The evidence upload feature makes it easier for the user to process evidence files, simply uploading via the API instead of using SSH to manually upload to a shared file system. Moreover, it enhances the integration between Turbinia and tools like dfTimewolf, which can now upload files to Turbinia via the API, making it easier to process evidence.
Storing evidence metadata in Redis allows us to have more information about how the requests happened for both analysis and debugging. The new evidence endpoints make it easy for users and developers to retrieve this information by using the different functions provided.
The ported commands bring parity to the Turbinia API in comparison to turbiniactl, so users can do the same actions without having to use the old client.
The reformatted commands make it easier to analyze information by organizing and simplifying the output. This will help developers debug and improve Turbinia, and users analyze information more easily and more quickly.
Possible future improvements
Through close collaboration with the Turbinia API and the Redis state manager, it was possible to identify some areas where future improvements could be made.
Implement TurbiniaRequest hash object in Redis
One possible way to improve the API would be to implement a TurbiniaRequest hash object in the state manager, similar to the TurbiniaEvidence object. This would have several advantages.
The current API gets information about a request by iterating over all tasks and deserializing each TurbiniaTask string object. This results in a runtime of O(m*n), where m is the number of tasks in the server and n is the number of attributes saved in each TurbiniaTask. If hashed TurbiniaRequest objects were implemented, the runtime would then fall to O(n), which is much faster as there can be millions of objects in the server.
Implementing the TurbiniaRequest should now be simpler as most of the functions created for the TurbiniaEvidence can be reused for requests.
Convert TurbiniaTask to hash objects in Redis
Another possible way to improve the API would be to convert the TurbiniaTask objects in Redis to hashes, as they have a faster runtime than strings, as shown in Table 1.
Similarly to implementing TurbiniaRequest objects, converting TurbiniaTask objects to hashes should be easier now because the functions for TurbiniaEvidence can be reused. Additionally, the evidence endpoints also provide features that are not available for TurbiniaTasks. Therefore, if TurbiniaTask objects are converted to hashes, the endpoints could be reused to add more functionality to TurbiniaTasks, such as the query endpoint, which is currently only available through the server-side script redis-tools.sh.
Store additional file upload metadata
Another update would be to automatically save the file hash of the uploaded evidence files in the Redis TurbiniaEvidence objects. This would make it easier to search for different requests concerning a certain file, as users would be able to search by the hash. The Evidence class already has a hash attribute, which is saved in Redis when the request is complete. Moreover, the upload function already checks if there are evidence objects with the same hash, to prevent uploading files twice and saving storage on the server. However, currently, the only way to update this attribute is to manually pass the hash of the file when making the request. However, this could be done automatically when uploading the file since the server would read the file and even create a hash if the user chooses to do so. Therefore, currently, this hash is discarded once the upload is complete, but it could be stored in Redis to be later used and searched for, which could prevent duplicate uploads of the same file and allow the user to query for file hash in Redis.
Comments
Post a Comment