Running GRR everywhrr
Running GRR everywhrr
Introduction
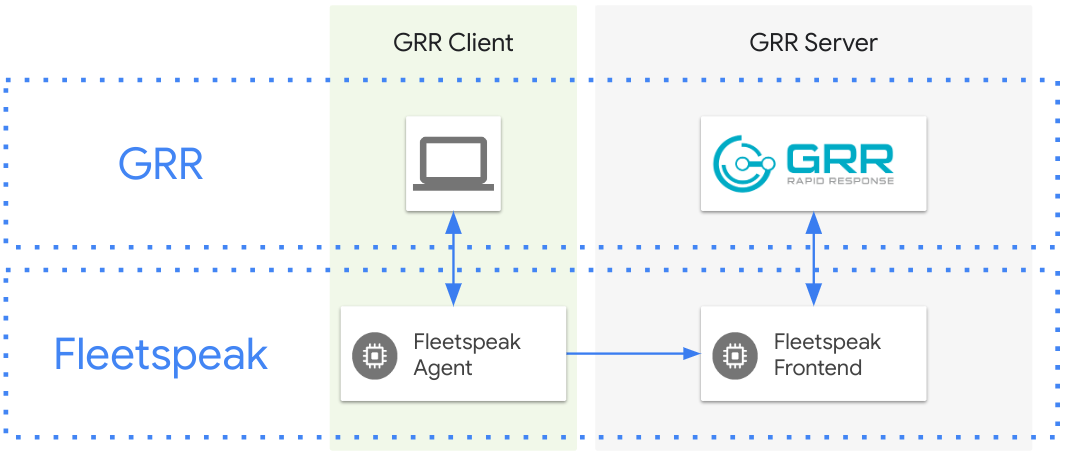
GRR Rapid Response (or GRR) is an incident response framework focusing on remote live forensics. GRR consists of client and server parts which communicate with each other leveraging the Fleetspeak communication framework.
In this blog post we investigate how GRR and Fleetspeak can be operated in a microservice based architecture. Real world deployments in complex enterprise networks often extend their requirements beyond GRR’s initial design of direct connectivity between the clients and the server. Choosing to leverage microservices and their related network architecture requirements introduces new communication layer challenges.
We will cover how Fleetspeak serves as the communication conduit for GRR to exchange messages with the fleet of clients it investigates. We will also explore novel network architectures that are enabled by a set of recently implemented Fleetspeak frontend (server) mode features.
And last but not least we will provide you with sample implementations and documentation pointers so you can try, test and adapt all of this for yourself.
Fleetspeak
In a nutshell, Fleetspeak is GRR’s communication layer. The Fleetspeak frontend (server) exchanges Protocol Buffer based messages with Fleetspeak agents (clients), providing GRR with a communication conduit.
Fleetspeak’s design has some unique networking requirements that benefit from a brief introduction so we can explore the network architecture challenges we might face as well as how they can be remedied.
To protect the sensitive nature of the information that is exchanged between the Fleetspeak agents and the Fleetspeak frontend the communication channel is protected with mutual Transport Layer Security (mTLS). Fleetspeak agents create a mTLS client side keypair on startup. The first 8 bytes of a sha256 hash of the mTLS public key then serve as the unique ClientID for the Fleetspeak agent (and by extension the GRR client). This tight link between the ClientID and public key can cause challenges when Fleetspeak is used in combination with a load balancer (see the diagram below).
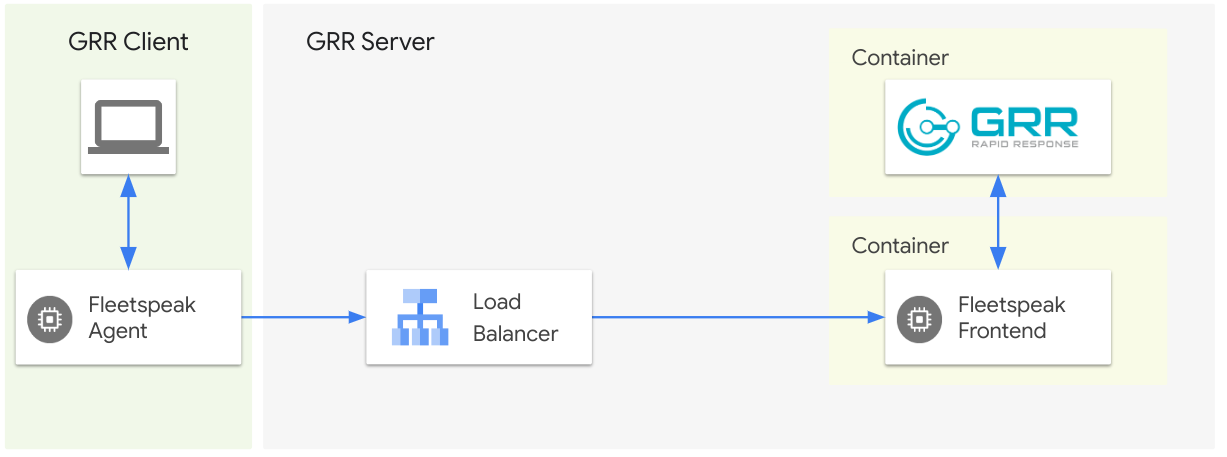
The challenge
Load balancers are an essential component of modern microservice based designs that deliver highly available applications. Working with organizations who implement GRR deployments for the first time we have increasingly noticed that they ask for a microservice based architecture that involves an application load balancer at the ingress edge of their infrastructure terminating the mTLS connection.
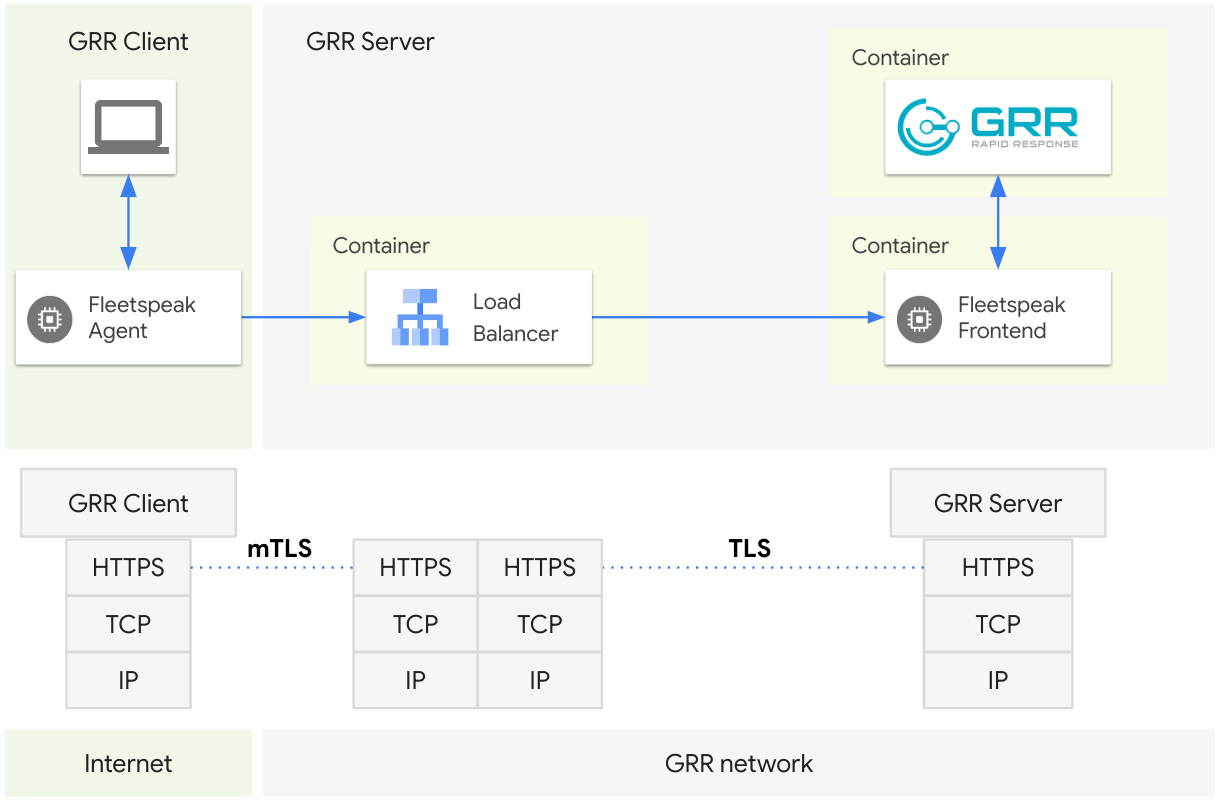
If we would use Transport Layer Security (TLS only, not mTLS) to satisfy the in-transit encryption requirement to protect the traffic between the load balancer and the Fleetspeak frontend, the Fleetspeak frontend is no longer able to receive the agent’s client certificate. This leads to the Fleetspeak frontend no longer being able to derive the sha256 hash of the mTLS public key which in turn leaves it unable to calculate the ClientID and identify the originating agent.
In some cases load balancers might offer the functionality to forward the client side certificate by other means. However, if they do not then this design will break Fleetspeak end-to-end.
The resolution
One possible way to resolve the challenge of no longer receiving the Fleetspeak agent’s client side mTLS certificate as it would if the connection terminated at the Fleetspeak frontend is to transmit the same certificate also via an additional HTTP header that can be forwarded end-to-end between the two parties.
The diagram below illustrates the case where a HTTP client_certificate_header is added to the end-to-end request from the Fleetspeak agent to the frontend. We also augmented the Fleetspeak frontend to extract the client side certificate from that additional header so it can again use the certificate to calculate the ClientID.
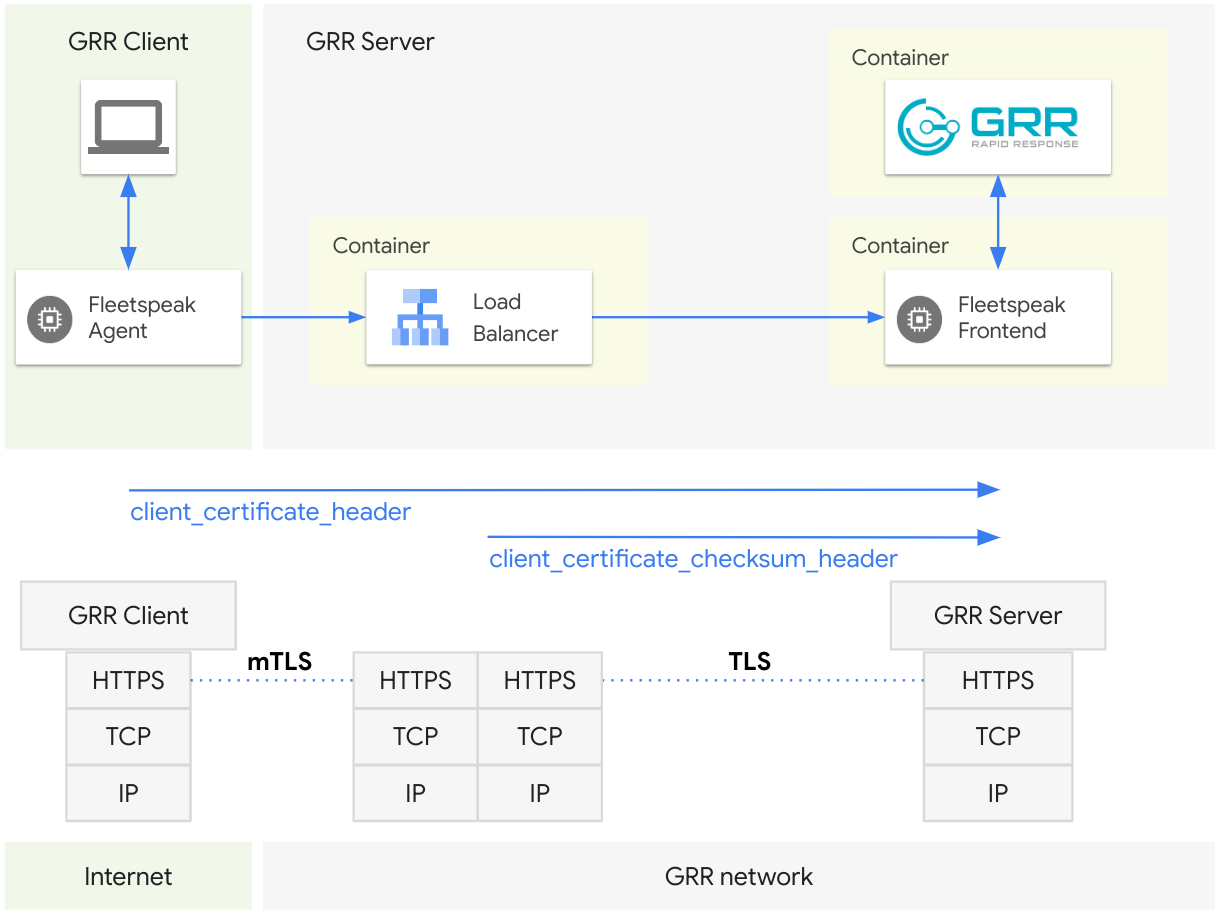
Some load balancers, while not forwarding the mTLS client side certificate, offer other features like adding a client certificate checksum (a.k.a. certificate fingerprint). One such example is the global layer 7 application load balancer on Google Cloud. It allows for configuring custom headers like for example the certificate fingerprint as the client_certificate_checksum_header.
Receiving the certificate’s checksum at the Fleetspeak frontend can be leveraged to provide an extra layer of security and confidence as it allows for proving that the client side certificate received by the load balancer is indeed identical to what the Fleetspeak agent has submitted via the additional HTTP client_certificate_header.
The Fleetspeak frontend can extract both the certificate and its checksum from these two new headers, then itself re-calculate the certificate checksum and compare it with the load balancer submitted checksum. If the two checksums are a match we can confidently verify that the received certificate is legitimate.
We have implemented the above scenario in a Docker Compose sandbox with Envoy as the proxy mimicking the layer 7 load balancer terminating the mTLS connection. Envoy also calculates the client side certificate checksum (the same way the Google Cloud layer 7 application load balancer does) and sends it on in the header of the upstream Fleetspeak frontend message.
We published the Docker Compose sandbox and its accompanying documentation on the online GRR documentation so you can view, replicate and/or adapt it to your own use cases.
The options
We found that there are several other network architecture permutations that involve an extra hop with proxies that might break the Fleetspeak end-to-end design. Therefore, we developed a suite of extra Fleetspeak frontend mode features that provide you with options that you can draw from to remedy many of these challenges.
These architectures typically require us to configure the Fleetspeak agent to add the client side certificate in the client_certificate_header.
You can do so by adding the parameter mentioned below to the Fleetspeak agent’s config.textproto configuration file.
// If set, the agent will add the client certificate into the chosen header
client_certificate_header: "YOUR_CLIENT_CERTIFICATE_HEADER_NAME"
In a similar fashion we augmented the Fleetspeak frontend to operate in different modes:
HTTPS header mode
For HTTPS (TLS) protected traffic scenarios between a proxy / layer 7 application load balancer and the Fleetspeak frontend.
This is the scenario we previously described in this blog post.
Cleartext header mode
For HTTP (cleartext) traffic scenarios between a proxy and the Fleetspeak frontend.
This would be useful for running the Fleetspeak frontend in a service mesh next to a sidecar proxy which is securing the traffic and forwarding the connection in cleartext to the Fleetspeak frontend running in the same Kubernetes pod.
Cleartext xfcc mode
For HTTP (cleartext) traffic scenarios between an Envoy proxy and the Fleetspeak frontend.
This would be useful for running Fleetspeak behind Envoy with the HttpConnectionManager forward_client_cert_details setting enabled which propagates the client side mTLS certificate in an x-forward-client-cert header.
You can configure the Fleetspeak frontend to operate in these modes by adding the parameters described below to the components.textproto configuration file.
// For HTTPS header mode
https_config: {
frontend_config: {
https_header_checksum_config: {
client_certificate_header: "YOUR_CERTIFICATE_HEADER"
client_certificate_checksum_header: "YOUR_CHECKSUM_HEADER"
}
}
}
// For cleartext header mode
https_config: {
frontend_config: {
cleartext_header_checksum_config: {
client_certificate_header: "YOUR_CERTIFICATE_HEADER"
client_certificate_checksum_header: "YOUR_CHECKSUM_HEADER"
}
}
}
// For cleartext xfcc mode
https_config: {
frontend_config: {
cleartext_xfcc_config: {
client_certificate_header: "x-forwarded-client-cert"
}
}
}
The next steps
We encourage you to try the architectural scenarios and the new Fleetspeak frontend mode features described above yourself.
They all come with their respective Docker Compose sandboxes so you can conveniently run them on your laptop, review and adapt them for your own use cases.
You find the the GRR sandbox from the example in this post here: https://grr-doc.readthedocs.io/en/latest/fleetspeak/sandbox.html
The Fleetspeak sandboxes that showcase the additional new Fleetspeak frontend mode features can be found here: https://github.com/google/fleetspeak/tree/master/sandboxes
Furthermore, we would like to bring our refreshed GRR website to your attention. You can find the new website with much more information on all things GRR here: https://www.grr-response.com
We hope you will find these new features helpful for your next GRR use case.
If you have any questions or suggestions then reach out on the GRR user group.
The links
The GRR sandbox: https://grr-doc.readthedocs.io/en/latest/fleetspeak/sandbox.html
The Fleetspeak sandboxes: https://github.com/google/fleetspeak/tree/master/sandboxes
The GRR website: https://www.grr-response.com
The Envoy documentation: https://www.envoyproxy.io/docs/envoy/latest/about_docs
Comments
Post a Comment