GRR with GCS Blobstore and Cloud Pub/Sub Service
GRR with GCS Blobstore and Cloud Pub/Sub Service
Authored by Dan Aschwanden and Mikhail Bushkov, copied with permission.
Introduction
In this article we provide a macro-level outline of how GRR Rapid Response (or GRR) can make use of Google Cloud Storage (GCS) Buckets for its blobstore as well as using Cloud Pub/Sub to communicate with Fleetspeak.
Leveraging GCS Buckets and Cloud Pub/Sub could be beneficial if you are looking for means to improve the runtime performance of a large-scale GRR deployment (i.e. with tens of thousands of clients). Both the GCS blobstore and Cloud Pub/Sub significantly reduce the utilization of the main GRR datastore and the amount of message processing.
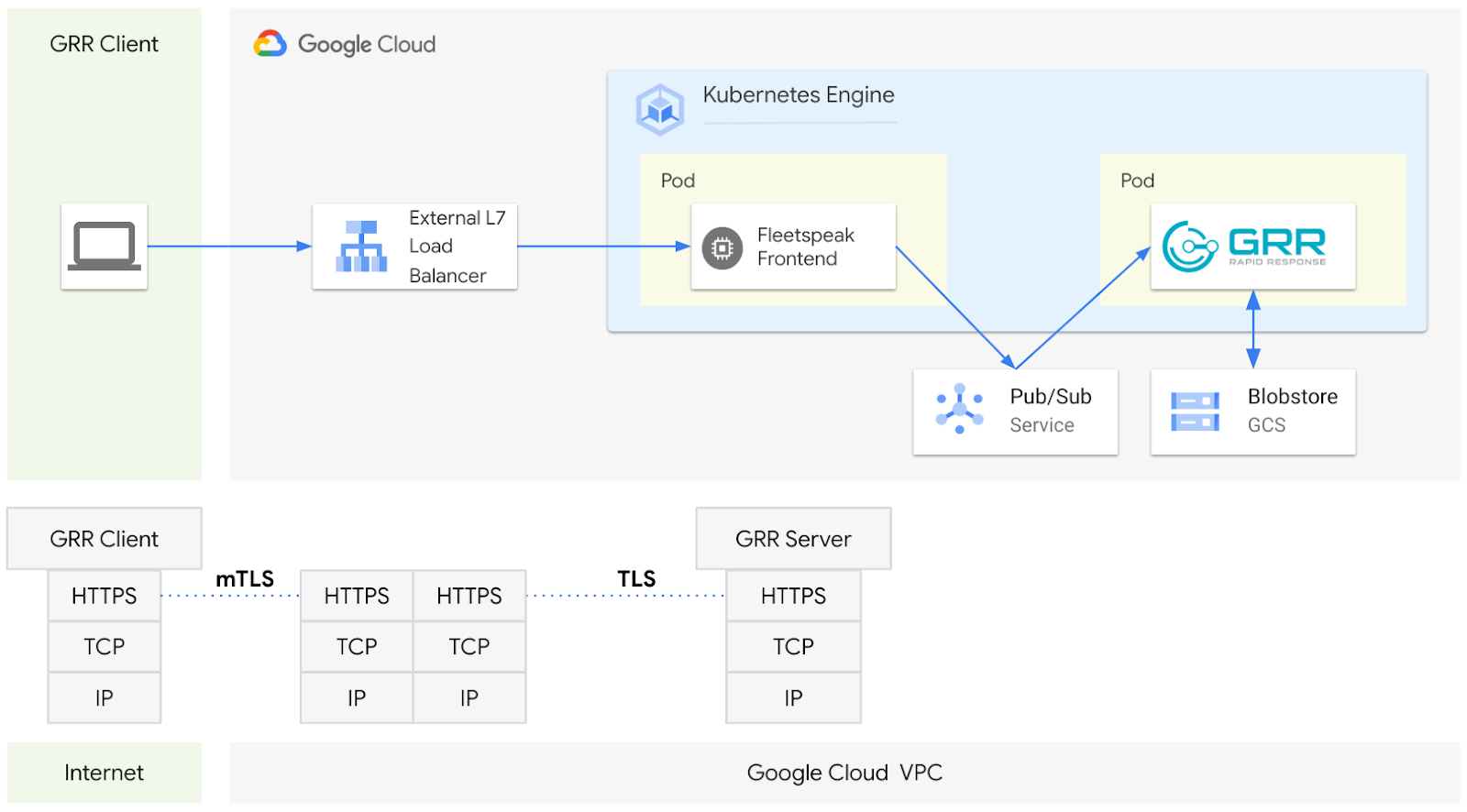
Figure 1 - GRR architecture with GCS Blobstore and Cloud Pub/Sub
We will also cover the topic of Google Kubernetes Engine (GKE) Workload Identity Federation which provides Kubernetes workloads with access to Google Cloud resources by using Identity and Access Management (IAM) federated identities instead of Service Account keys. As such GRR workloads running on GKE can securely authenticate to supported Google Cloud APIs (like GCS and Pub/Sub) without the overhead of having to manage Service Account credentials.
You can find a GRR sample implementation that leverages these concepts in the OSDFIR Infrastructure repository and follow the step-by-step setup instructions in the accompanying README file.
The three key benefits that we would like you to take away from the strategies described in this article are:
Using GCS as the blobstore will take a lot of pressure off GRR’s MySQL database and reduce its storage footprint dramatically.
Leveraging Cloud Pub/Sub to decouple GRR from Fleetspeak allows them to run asynchronously with the Pub/Sub Topic message buffering capabilities absorbing the communication spikes.
And last but not least, applying Workload Identity Federation for GKE provides a secure and convenient authentication mechanism for GRR Kubernetes workloads to access Google Cloud resources.
GRR blobstore with GCS Buckets
When you first install GRR to learn about its features and functionality you are unlikely to be concerned about scaling its operation under load. However, when you install GRR with the intention to run it as your large-scale incident response framework for performing remote live forensics on your enterprise/corporate fleet then performance considerations warrant some deliberate choices.
By default GRR will use MySQL as its datastore and use the same MySQL instance also as its blobstore to persist the blobs that it retrieves during your investigations. Blobs are retrieved every time files are collected from endpoints, with each blob corresponding to a 512 KiB chunk of the file’s content. Depending on your usage pattern this might cause the size of your MySQL instance to grow rapidly with the blobstore consuming the majority of the database storage space.
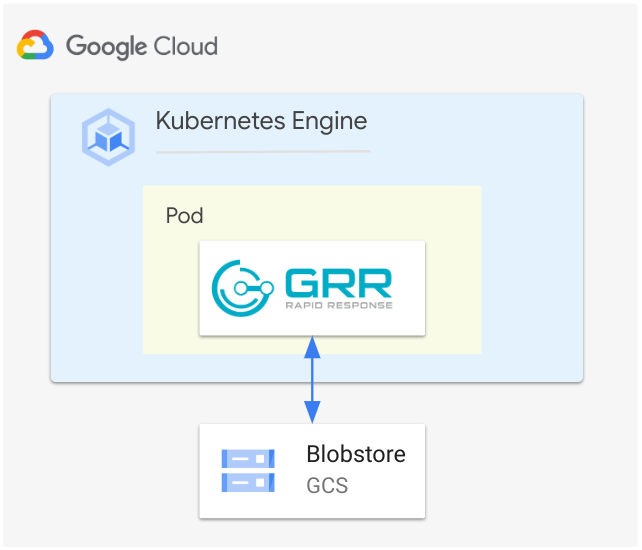
Figure 2 - GRR with GCS Bucket blobstore
In case you are aiming for a large-scale GRR deployment on Google Cloud we recommend that you consider enabling GCSBlobStore as GRR’s blobstore storage option.
Assuming you have already created a GCS Bucket in your Google Cloud Project then you can enable the use of the GCSBlobStore feature by setting the Blobstore.implementation, Blobstore.gcs.project and Blobstore.gcs.bucket parameters in the GRR configuration file as outlined below.
Database.implementation: MysqlDB
# Blobstore.implementation: DbBlobStore --> this is the default
Blobstore.implementation: GCSBlobStore
Blobstore.gcs.project: YOUR_GOOGLE_CLOUD_PROJECT_ID_HERE
Blobstore.gcs.bucket: YOUR_GOOGLE_CLOUD_STORAGE_BUCKET_HERE
Note that GRR will need to be configured with the appropriate Google Cloud Identity and Access Management (IAM) permissions to access the GCS Bucket. Further down in this article we will cover how this can be achieved with Workload Identity Federation for GKE.
GRR Services with Cloud Pub/Sub
Fleetspeak is GRR’s communication layer and delivers messages through Server Services. The default setting for Fleetspeak is to deliver the messages through gRPC. While this mode of communication works well in general it might lead to backlogs in high throughput scenarios due to the tight coupling of the GRR and Fleetspeak server components and the lack of flow control mechanisms in the GRR-Fleetspeak gRPC protocol implementation.
To mitigate any communication channel blockages we can enable the GRR Services to use Cloud Pub/Sub for delivering the messages from Fleetspeak. Decoupling GRR from Fleetspeak allows the server components to run asynchronously with the Pub/Sub Topic message buffering capabilities absorbing any communication spikes.
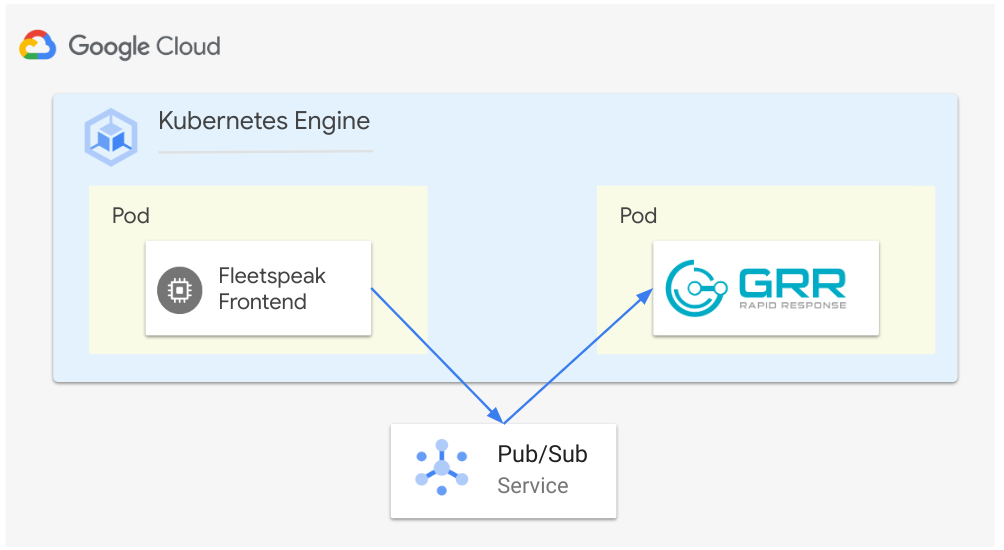
Figure 3 - GRR with Cloud Pub/Sub service Fleetspeak communication
After you created a Google Cloud Pub/Sub Topic and a Pub/Sub Subscription in your Google Cloud Project you can configure GRR by setting the Server.fleetspeak_cps_enabled, Server.fleetspeak_cps_project, Server.fleetspeak_cps_subscription and Server.fleetspeak_cps_concurrency parameters in the in the GRR configuration file as outlined below.
Server.fleetspeak_cps_enabled: true
Server.fleetspeak_cps_project: YOUR_GOOGLE_CLOUD_PROJECT_ID_HERE
Server.fleetspeak_cps_subscription: YOUR_GOOGLE_CLOUD_PUBSUB_SUBSCRIPTION_HERE
Server.fleetspeak_cps_concurrency: 10
Similarly, you can configure the Fleetspeak Server Services setting the parameters as listed below.
services {
name: "GRR"
factory: "CPS"
config {
[type.googleapis.com/fleetspeak.cpsservice.Config] {
project: "YOUR_GOOGLE_CLOUD_PROJECT_ID_HERE"
topic: "YOUR_GOOGLE_CLOUD_PUBSUB_TOPIC_HERE"
}
}
}
Like accessing the GCS Bucket for its blobstore as described above, GRR will also need the appropriate Google Cloud IAM permissions to interact with the Pub/Sub Topic and Subscription.
In the next section we will explore how the GKE Workload Identity Federation feature provides a secure and convenient authentication mechanism to access Google Cloud resources.
GKE Workload Identity Federation
Google Kubernetes Engine (GKE) Workload Identity Federation provides Kubernetes workloads with access to Google Cloud resources by using Identity and Access Management (IAM) federated identities instead of Service Account keys.
Thanks to the fact that Google Cloud abstracts the intricate details and complexities, it becomes quite straightforward to configure your GKE cluster with the Workload Identity Federation functionality. The online documentation guides you through the steps required to configure your GKE cluster with the Workload Identity Federation settings.
Furthermore, the sample GRR on GKE implementation that you can find in the OSDFIR Infrastructure repository is implementing this best practice security pattern so you can study a working end-to-end example in practice.
Nevertheless, it is helpful to gain a high level understanding of the key aspects of Workload Identity Federation. The diagram below provides a distilled overview of the key components involved in the process.
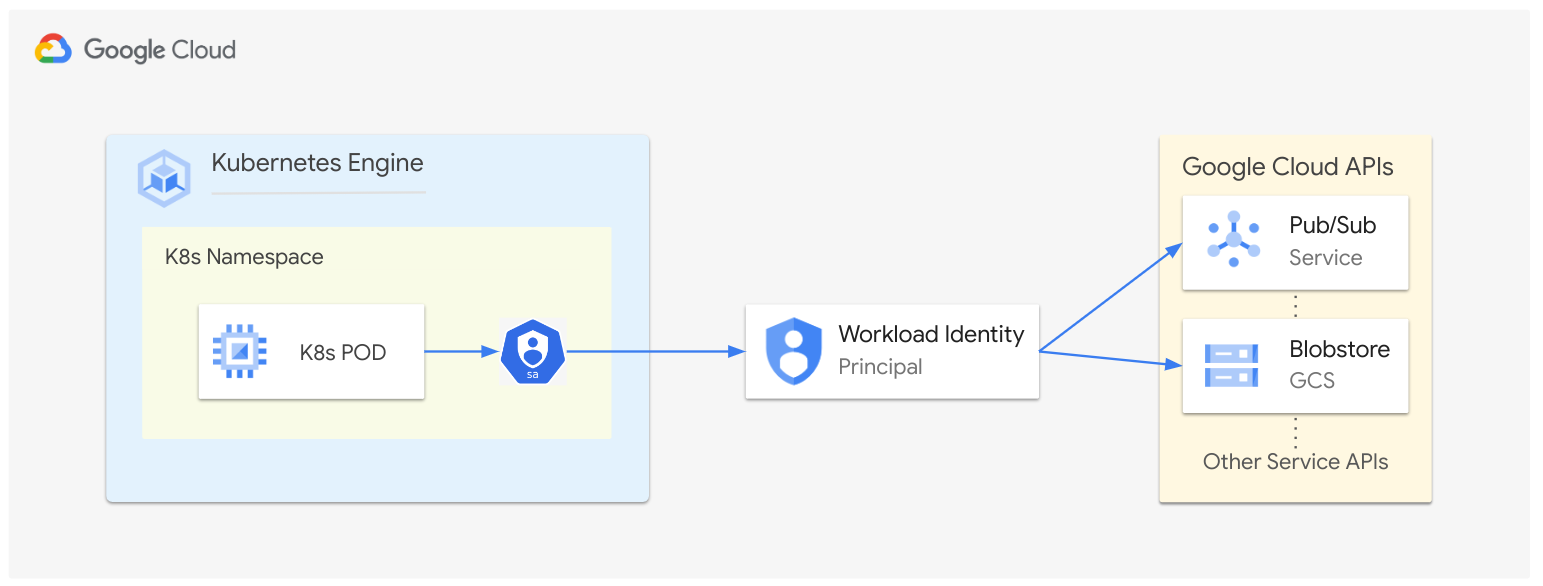
Figure 4 - GKE Workload Identity Federation
In a nutshell, Workload Identity Federation for GKE utilizes IAM allow policies that grant access to a specific Google Cloud resource via a principal that corresponds to an application's identity (like in our case a GRR Kubernetes Pod).
For example, you can give read-write IAM permissions via the roles/storage.admin IAM role on the blobstore Cloud Storage Bucket to the GRR Pods that run under the grr-sa Kubernetes Service Account.
In a similar fashion you can allocate the roles/pubsub.subscriber and roles/pubsub.publisher roles that allow for reading from Cloud Pub/Sub Subscription and writing to the Cloud Pub/Sub Topic for the communication between Fleetspeak and GRR.
For a comprehensive list of Google Cloud resources that support allow policies, see Resource types that accept allow policies.
Summary
In this short article we looked into how you can empower your large-scale GRR deployment by employing two optimization strategies.
First, we covered how to configure GRR to use a GCS Bucket as its blobstore as opposed to storing the blobs in the MySQL datastore. This will take a lot of pressure off the MySQL database and reduce its storage footprint dramatically.
As a second optimization strategy we covered how GRR can use Cloud Pub/Sub for communicating with Fleetspeak. As opposed to using gRPC as its default communication mechanism, leveraging Pub/Sub decouples GRR from Fleetspeak and allows them to run asynchronously by absorbing any communication spikes with the Pub/Sub Topic message buffering capabilities.
Last but not least, we also explored how GKE Workload Identity Federation can provide a secure and convenient authentication mechanism for GRR Kubernetes workloads to access Google Cloud resources without having to rely on Service Account keys. This enhances both the operational ease and the security posture of your GRR implementation.
We hope that this article helps you augment the resilience of your large-scale GRR deployment by optimizing the blobstore and Fleetspeak communication performance while also applying best practices for accessing Google Cloud resources from within your cluster workloads.
You can find much more information on all things GRR on the website here: https://www.grr-response.com
If you have any questions or suggestions then reach out on the GRR user group.
Links
GRR documentation: https://grr-doc.readthedocs.io
GRR website: https://www.grr-response.com
GRR repo: https://github.com/google/grr
Fleetspeak repo: https://github.com/google/fleetspeak
OSDFIR Infrastructure repo: https://github.com/google/osdfir-infrastructure/
GRR Rapid Response (GRR)
GRR Rapid Response (or GRR) is an incident response framework focusing on remote live analysis. GRR consists of client and server parts which communicate with each other leveraging the Fleetspeak communication framework.
Comments
Post a Comment