Life of a GRR message
Life of a GRR message
Introduction
In this article a macro-level outline of how GRR Rapid Response (or GRR) messages are delivered via Fleetspeak as the communication conduit is provided.
The details covered in this article will be valuable for scenarios where you need to debug or troubleshoot functionalities of GRR and/or Fleetspeak. Furthermore, the content in this article is also suitable as a first introduction to GRR and Fleetspeak. So whether you only get started or you are a seasoned practitioner we hope you will be able to take away something useful from this article.
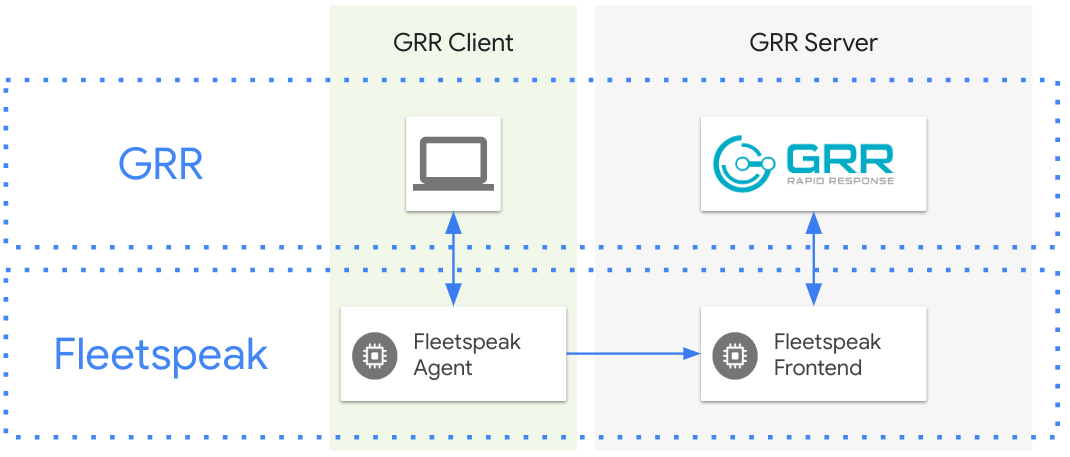
Fleetspeak does much of the heavy lifting for the GRR message exchange. Its design has some unique networking requirements which we already covered in a previous article.
In this article we dive into the nature of the persistent connections that Fleetspeak clients (aka agents like GRR) use to communicate with the Fleetspeak server (aka frontend) and hence enable GRR to deliver its message payloads.
GRR Rapid Response
GRR Rapid Response (or GRR) is an incident response framework focusing on remote live analysis. GRR consists of client and server parts which communicate with each other leveraging the Fleetspeak communication framework.
Fleetspeak
In a nutshell, Fleetspeak is GRR’s communication layer. The Fleetspeak frontend (server) exchanges Protocol Buffer based messages with Fleetspeak agents (clients), providing GRR with a communication conduit.
Fleetspeak frontends keep a registry of Fleetspeak agents that they are connected to. Whenever frontends have work to be delivered for a particular agent - and this agent is already connected - the message will be proactively sent through the existing connection. This way new work can be sent to the Fleetspeak agent with minimal latency.
Connectivity
Fleetspeak agents open long living TCP streaming connections which the agents will close and reopen every 10 minutes to cater for recovery from potential connectivity issues.

The way the Fleetspeak agents establish the long living TCP connection is to send a HTTP POST request with an Expect: 100-continue header.
Common Fleetspeak communication issues can arise when intermediate network actors (like proxies) consume the Expect: 100-continue header (i.e. respond on their own behalf) as opposed to forward the header all the way to the Fleetspeak frontend. A commonly known culprit is the envoy proxy, which is often used in a service mesh or a comparable network architecture. If your Fleetspeak communication path includes envoy proxies then make sure that you enable the proxy_100_continue configuration setting.
A quick way to confirm that the streaming connection is set up and working correctly (end-to-end from the agent to the frontend) is to run a simple GRR Flow (like ListProcesses) and take note of how fast the results are being returned. The latency should be within the order of seconds.
With this context in mind let’s take a closer look at the details of GRR message exchange.
From GRR client to GRR server
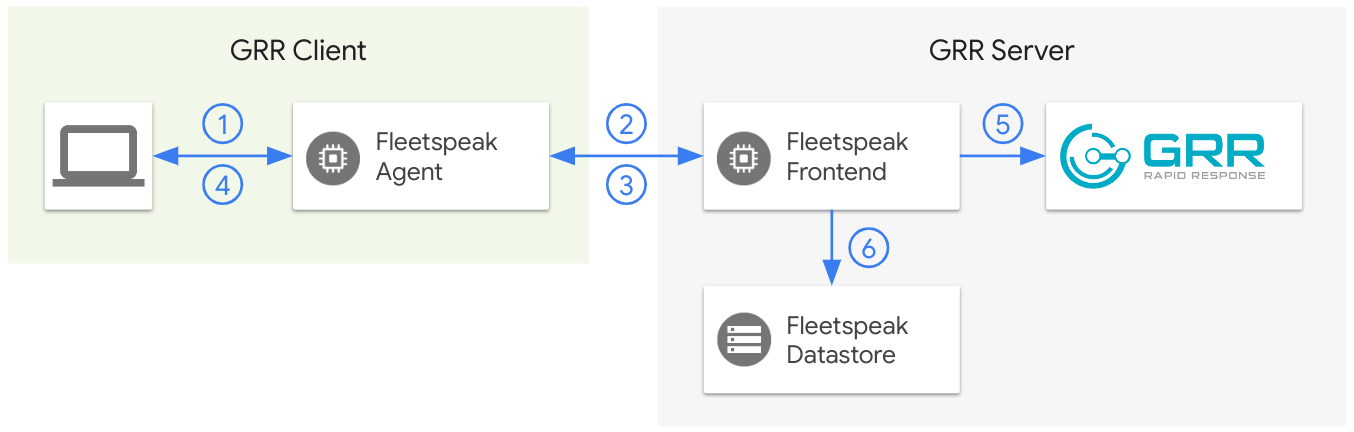
The GRR client hands the Fleetspeak agent a message for delivery.
Clients can connect to the Fleetspeak agent either through a Daemon service or a Socket service. GRR uses the Daemon service mode to connect to Fleetspeak.
The Fleetspeak agent starts daemon services as a subprocess during its own startup. The communication between the client and the agent is via input/output file descriptors.
The Fleetspeak agent does not start socket services. The communication in socket service mode is handled via UNIX sockets.
The Fleetspeak agent sends the message to the Fleetspeak frontend.
Currently, Fleetspeak offers two connection options, polling and streaming. Polling will be deprecated. Only streaming mode provided by the SteamingConnector should be used.
The Fleetspeak frontend acknowledges the message to the Fleetspeak agent.
The Ack message is returned in the frontend's readLoop.
The Fleetspeak agent sends the acknowledgement to the GRR client.
Acknowledgments confirm the delivery of sent messages in a MessageAckData proto.
The Fleetspeak frontend processes the message and delivers it to the GRR server.
The actual processing is done through the implementation of the fleetspeak.server.service.Service interface which comes in both a grpc and a pubsub flavor.
The Fleetspeak frontend serializes the message and persists it in the datastore.
Messages that can not be delivered are scheduled for reprocessing later.
From GRR server to GRR client
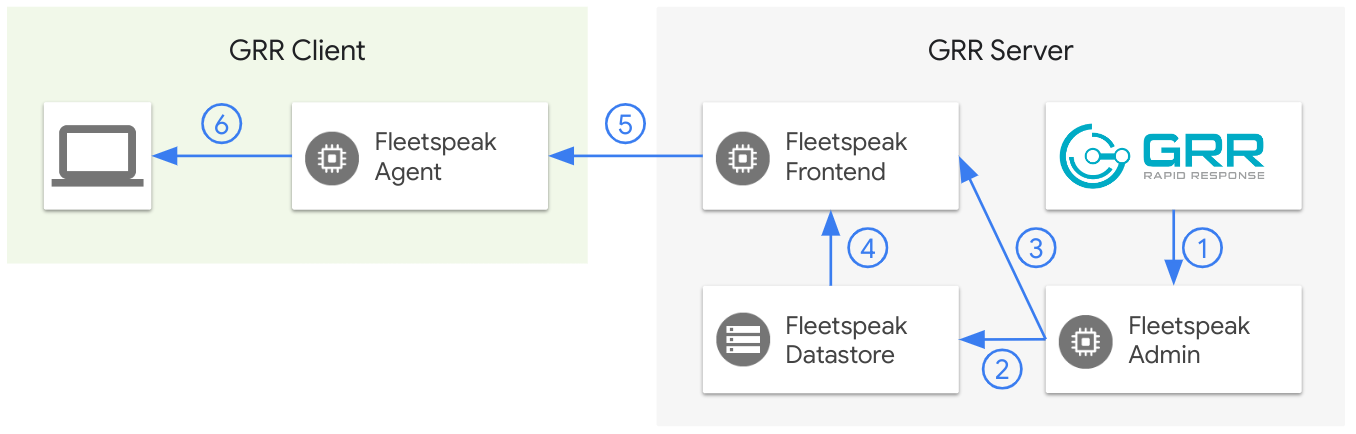
The GRR server sends a message to the Fleetspeak admin.
The GRR server uses the Admin.InsertMessage method exposed on the Fleetspeak Admin gRPC interface to deliver the message.
The Fleetspeak admin immediately persists the message in the Fleetspeak datastore.
The Fleetspeak admin notifies the Fleetspeak frontend of the message to be delivered.
The Fleetspeak frontend picks up the notification in its notifyLoop and retrieves the message from the Fleetspeak datastore.
The Fleetspeak frontend sends the message to the Fleetspeak agent.
If the destination Fleetspeak agent is currently offline, then pending messages will be delivered as soon as the agent reconnects.
The Fleetspeak agent delivers the message to the GRR client.
Summary
In this short article we covered a lot of ground about how GRR clients communicate with their server side. We introduced the key aspects of the connectivity and also covered the main steps of how messages are delivered in both directions, both from the GRR clients to the GRR server and also the other way around.
We hope that this article helps to equip you with useful knowledge about the inner workings of GRR and Fleetspeak that you will find helpful in many practical scenarios when working with GRR.
Links
GRR documentation: https://grr-doc.readthedocs.io
GRR website: https://www.grr-response.com
GRR repo: https://github.com/google/grr
Fleetspeak repo: https://github.com/google/fleetspeak
Envoy documentation: https://www.envoyproxy.io/docs/envoy/latest/about_docs
Comments
Post a Comment